
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Hyperband bracket assignment using hash in parallelization
See original GitHub issueI think there could be a problem when using Hyperband pruner in parallelization. In Hyperband, each trial is assigned to the bracket by computing hash(“{}{}”.format(study.studyname, trial.number). However, the hash gives different value for the same input when executed on different terminal. A trial n, for example, could be assigned to the bracket 1 at process 1 and the bracket 2 at process 2 , which ruins the benefits of using Hyperband pruner instead of the SuccesiveHalving pruner.
Expected behavior
A trial needs to be assigned to the identical bracket among each process.
Environment
- Optuna version: 2.10.0
- Python version: 3.6.9
- OS: Linux
Error messages, stack traces, or logs
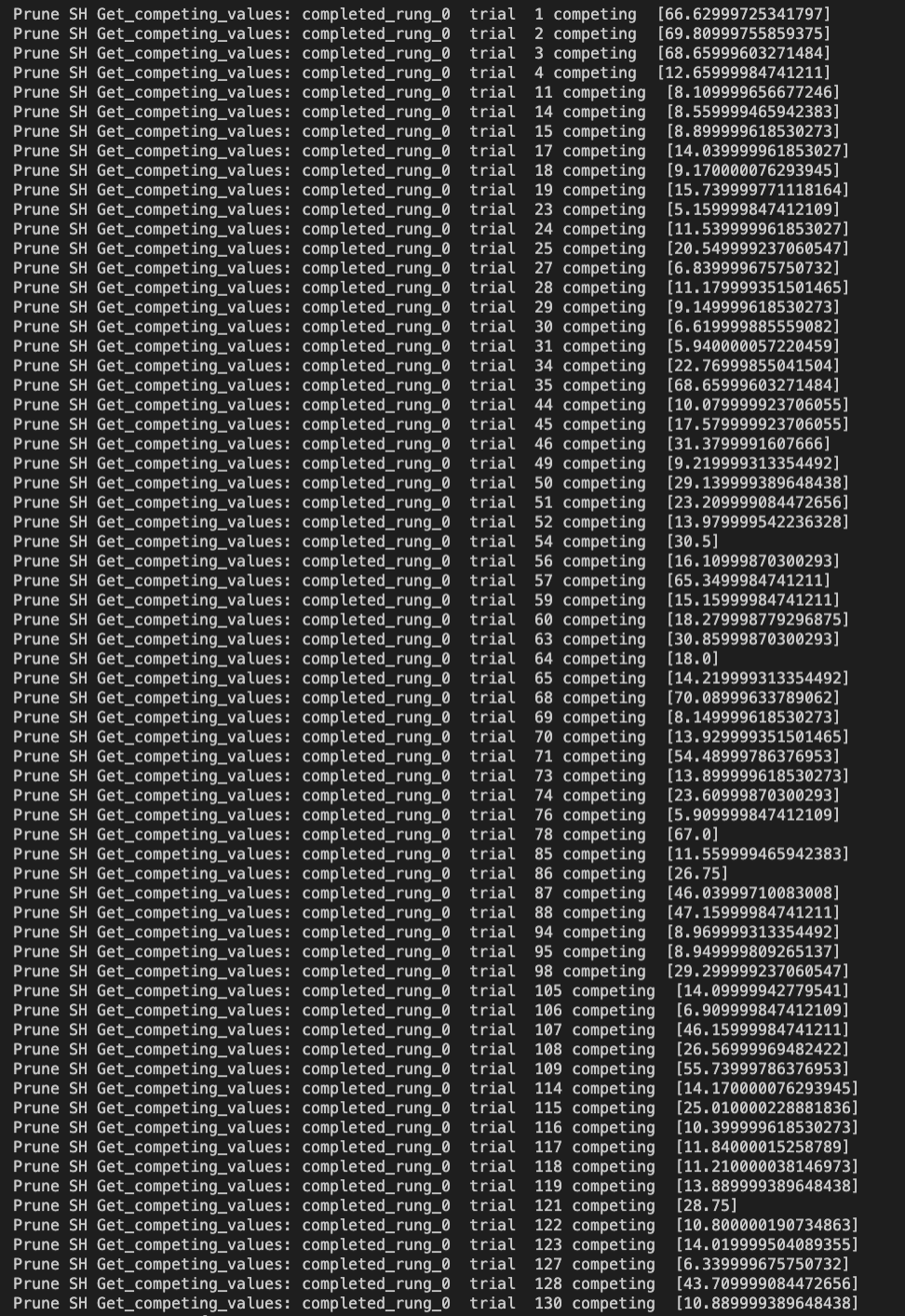
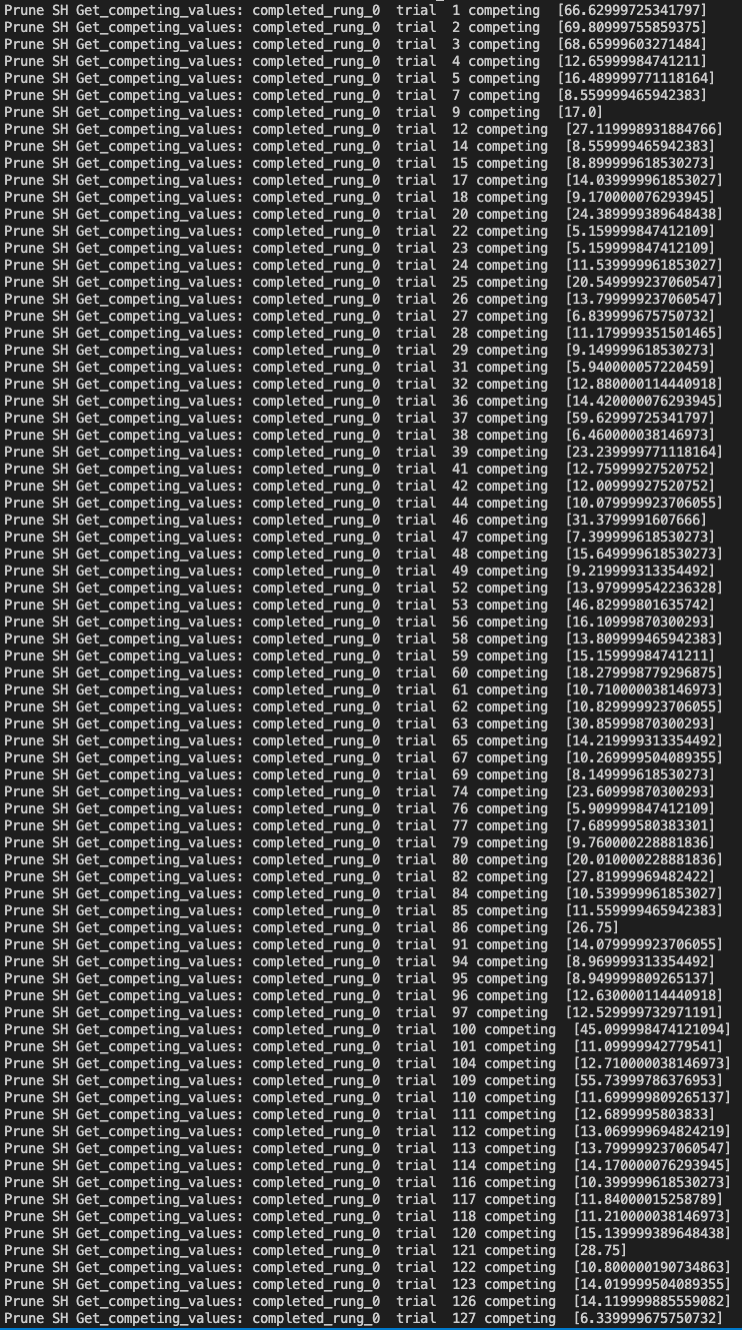
I attached an custom-made log that I’d added in the SuccessiveHalving code, which is a part of the Hyperband. The trials 1, 2, 3, 4 were included in bracket 1 at both process 1 and 2 However, the trials 5, 7, 9 were included in the bracket only at process 2.
Trials for bracket 1 at process 1
Trials for the same bracket 1 at process 2
Steps to reproduce
- Add the following codes at the beginning of the def _get_competing_values( ) in the _successive_halving.py
for t in trials :
if rung_key in t.system_attrs:
compet = [t.system_attrs[rung_key]]
print(' Prune SH Get_competing_values: '+ rung_key, ' trial ',t.number,'competing ',compet)
- Check if the trials consisting of a bracket differs among each process
Additional context (optional)
As you can see here, it was due to the update that hash randomization is turned on after python version 3.3. Of course, the randomization could be turned off by setting the PYTHONHASHSEED=0 when executing the python script. Since I did not see any warning or suggestion about this problem, I would like to ask if my assertion was legit.
Issue Analytics
- State:

- Created 2 years ago
- Reactions:1
- Comments:22 (15 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
@hvy I took a brief benchmark using
timeit.The result shows that
hashlib.sha*functions were 7 to 8 times slower thanhash(). This is mainly becausehashlib.sha*returns a byte array and we need to convert it to an integer to calculate the remainder divided byself._total_trial_allocation_budget. @c-bata suggested an alternative functionbinascii.crc32, and it seems a bit slower thanhash, but it is much faster thanhashlib.sha*. I think we don’t need cryptographic hash functions for this purpose, andbinascii.crc32may be a reasonable choice among them.Alternatively, we may just take
trial.number % self._total_trial_allocation_budgetas suggested in https://github.com/optuna/optuna/pull/809#discussion_r361076742. I’m not sure the randomness ofhashfunctions affects the search performance.hashhashlib.md5hashlib.sha1hashlib.sha256hashlib.sha512binascii.crc32timeit benchmarking
You’re right, and a simple mod might also suffice. The logical change is probably a matter of a few lines of code (if not one), but we probably want to take a benchmark during the course of this PR, whichever approach we opt for. If a contributor is willing to work on this issue, a core maintainer could perhaps step in and help with setting up the benchmark, or alternatively, run the benchmark for him/her. (It’d be interesting to compare different bracket assignment algorithms for sure)