
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Improve flow runner to enable more task parallelism
See original GitHub issueDescription
Flatten has edge cases which sometimes causes tasks to run sequentially. I have identified 2 cases below which demonstrate the unusual behavior. In the test case, I flatten the output of a mapped seed task and execute 3 dependent sleep tasks which are intended to run in parallel. The implementation of the DAG has an influence on whether the job executes in parallel or not
Expected Behavior
fast_flow demonstrates the expected behavior. Upon launch, all three print statements show up immediately.
slow_flow adds one additional step by storing flatten into an array, and retrieving it by index. This has the same DAG as fast_flow but this ends up executing sequentially.
slow_flow_2 is identical to fast_flow but removes the map task. It is odd that downstream tasks are required for parallel execution.
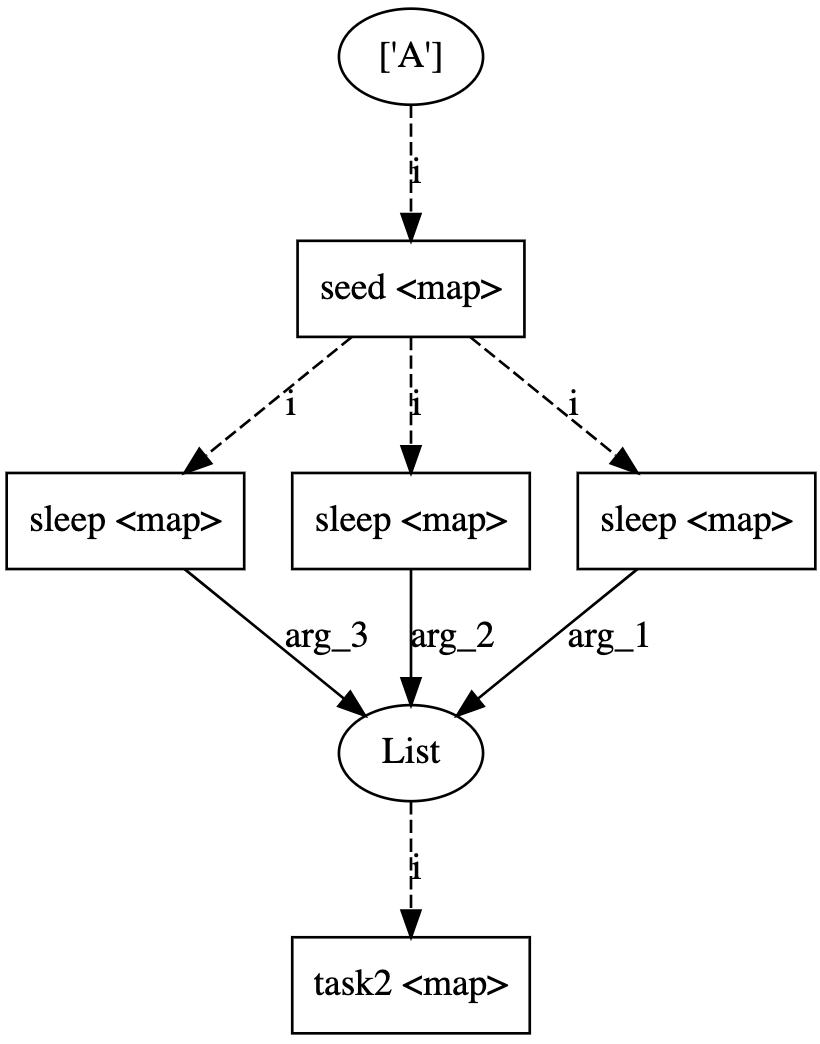
Reproduction
import time
from prefect import task, Flow, flatten, unmapped
from prefect.engine.executors import LocalDaskExecutor
@task
def seed(i):
return [i]
@task
def sleep(i, sleep_time):
print(f'Sleep {sleep_time}')
time.sleep(sleep_time)
print(f'Finished {sleep_time}')
return [i]
@task
def task2(i):
print(f'Task2 {i}')
print(f'Finished {i}')
return [i]
with Flow("slow_flow") as slow_flow:
start = ['A']
inputs = flatten(seed.map(start))
all_paths = []
for i in (10, 11, 12):
foo = [flatten(sleep.map(inputs, unmapped(i)))]
all_paths.append(foo[0])
sleep_out = flatten(all_paths)
task2.map(sleep_out)
with Flow("fast_flow") as fast_flow:
start = ['A']
inputs = flatten(seed.map(start))
all_paths = []
for i in (10, 11, 12):
all_paths.append(sleep.map(inputs, unmapped(i)))
sleep_out = flatten(all_paths)
task2.map(sleep_out)
with Flow("slow_flow_2") as slow_flow_2:
start = ['A']
inputs = flatten(seed.map(start))
all_paths = []
for i in (10,11,12):
all_paths.append(sleep.map(inputs, unmapped(i)))
fast_flow.run(executor=LocalDaskExecutor(scheduler='threads'))
#slow_flow.run(executor=LocalDaskExecutor(scheduler='threads'))
#slow_flow_2.run(executor=LocalDaskExecutor(scheduler='threads'))
Environment
Prefect - 0.13.7 python 3.8.2
Issue Analytics
- State:

- Created 3 years ago
- Reactions:5
- Comments:10
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Please don’t ping our team directly. We triage handling of these issues internally.
As the warning displays,
flow.run()calls when using theDaskExecutormust be guarded by a__main__block. This is a requirement for how they package scripts to send to workers.This issue was closed because it has been stale for 14 days with no activity. If this issue is important or you have more to add feel free to re-open it.