
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Provide documentation for running on k8s with run-config based flow
See original GitHub issueDescription
As described in https://github.com/PrefectHQ/prefect/issues/3509, we have problems enabling debug level logging for our DaskKubernetesEnvironment.
Therefore, we tried out flow.run_config, which was successful.
However, it seems like tasks are not parallelized properly.
We tried both flow.executor = DaskExecutor() and flow.executor = LocalDaskExecutor(num_workers=...), but got the following gantt charts:
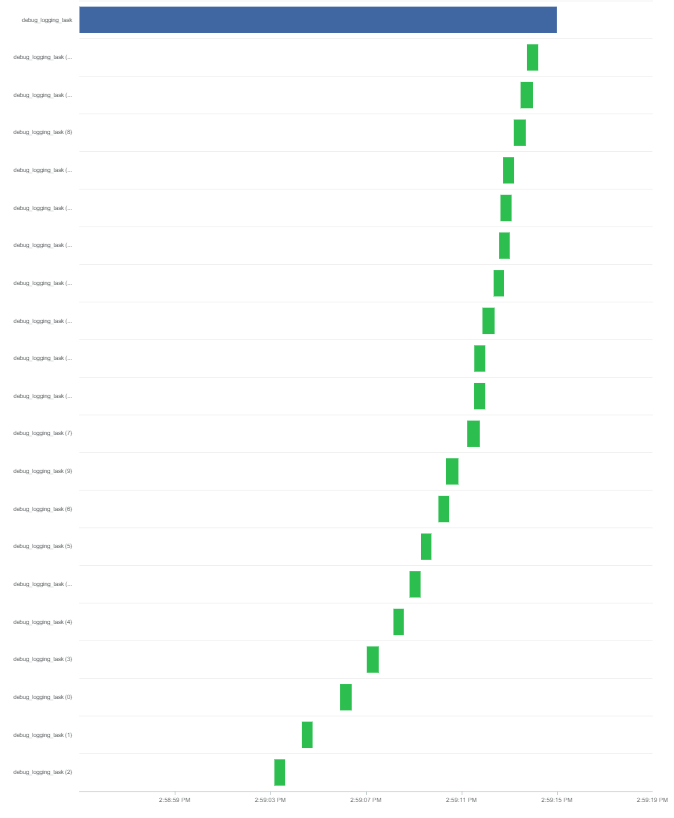
flow.run_config :
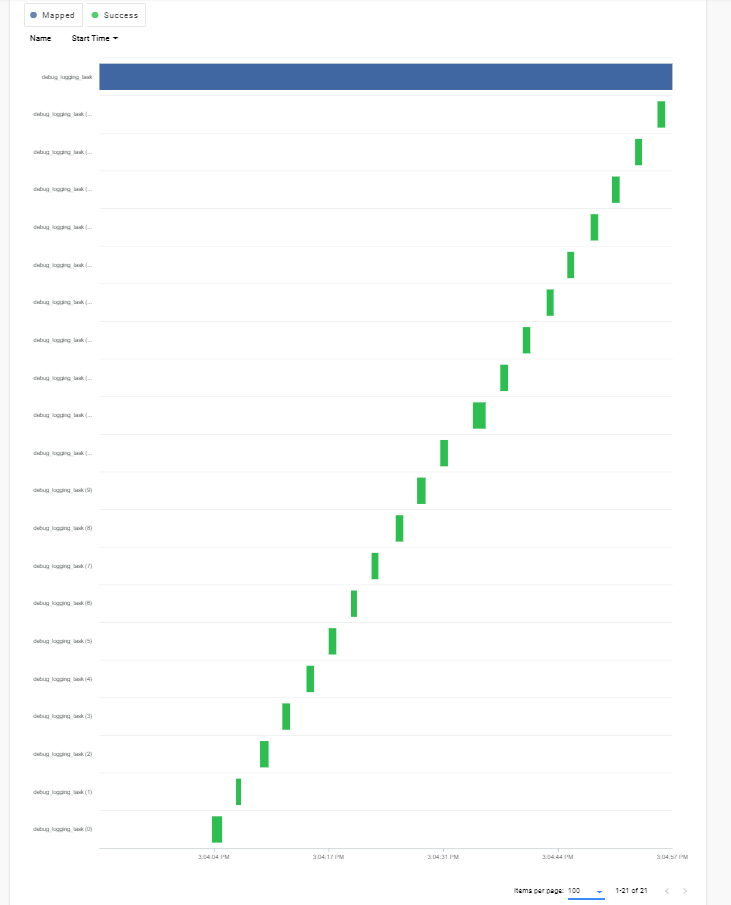
flow.run_config - flow.executor = DaskExecutor() :
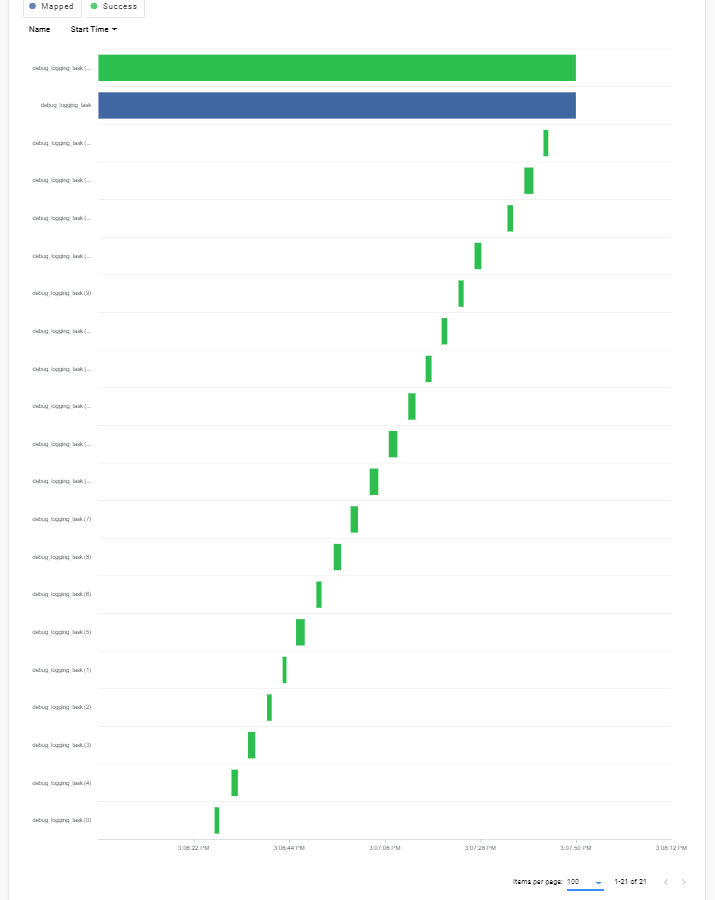
flow.run_config - flow.executor = LocalDaskExecutor(num_workers=20) :
Although the tasks do parallelize for the LocalDaskExecutor, they take 20 times as long (36 s instead of 1-2 seconds).
Expected Behavior
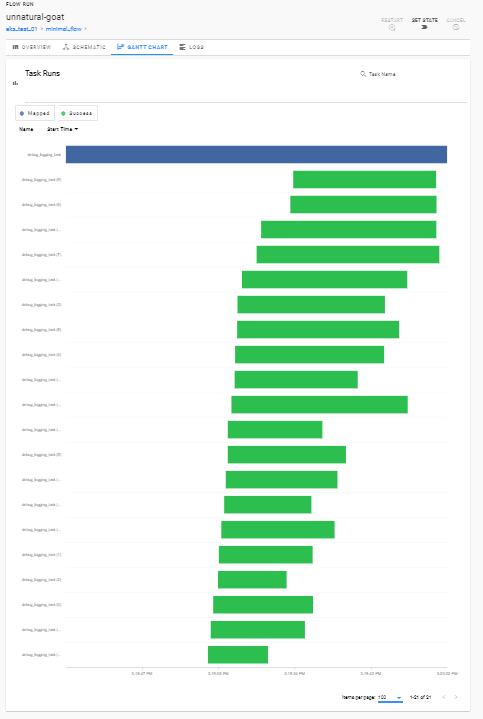
- screenshot of parallelized run (albeit without debug level logging)
DaskKubernetesEnvironment:
Reproduction
- add parallelization to minimal example
Environment
- AWS EKS cluster
## KUBERNETES
prefect_agent_labels = {
"app": "prefect-agent",
}
prefect_agent_deployment = k8s.apps.v1.Deployment(
"prefect-agent",
spec={
"replicas": 1,
"selector": {
"match_labels": prefect_agent_labels
},
"template": {
"metadata": {
"labels": prefect_agent_labels
},
"spec": {
"containers": [{
"name": "agent",
"resources": {
"limits": {
"cpu": "100m",
"memory": "128Mi",
}
},
"args": [
"prefect agent start kubernetes",
],
"command":[
"/bin/bash", "-c"
],
"env":[
{"name": "PREFECT__CLOUD__AGENT__AUTH_TOKEN",
"value": PREFECT_AGENT_AUTH},
{"name": "PREFECT__CLOUD__API",
"value": "https://api.prefect.io", },
{"name": "NAMESPACE",
"value": "default", },
{"name": "IMAGE_PULL_SECRETS",
"value": "", },
{"name": "PREFECT__CLOUD__AGENT__LABELS",
"value": PREFECT_AGENT_LABELS, },
{"name": "PREFECT__LOGGING__LEVEL",
"value": "DEBUG"},
{"name": "PREFECT__CLOUD__LOGGING__LEVEL",
"value": "DEBUG"},
{"name": "JOB_MEM_REQUEST",
"value": "", },
{"name": "JOB_MEM_LIMIT",
"value": "", },
{"name": "JOB_CPU_REQUEST",
"value": "", },
{"name": "JOB_CPU_LIMIT",
"value": "", },
{"name": "IMAGE_PULL_POLICY",
"value": "", },
{"name": "SERVICE_ACCOUNT_NAME",
"value": "", },
{"name": "PREFECT__BACKEND",
"value": "cloud", },
{"name": "PREFECT__CLOUD__AGENT__AGENT_ADDRESS",
"value": "http://:8080", },
],
"image": PREFECT_AGENT_IMAGE,
#"image": "prefecthq/prefect:0.12.3-python3.6",
"image_pull_policy": "Always",
"liveness_probe": {
"failure_threshold": 2,
"http_get": {
"path": "/api/health",
"port": 8080
},
"initial_delay_seconds": 40,
"period_seconds": 40,
},
}]
}
}
},
opts=pulumi.ResourceOptions(provider=k8s_provider)
)
Optionally run prefect diagnostics from the command line and paste the information here. -->
Issue Analytics
- State:

- Created 3 years ago
- Comments:7
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Definitely! I’ll ping you once we have some docs up. I’m going to change this issue to a docs issue for running on k8s run config, since that’ll be mostly taking the above info and converting to docs 😃.
Hi @Zaubeerer, sorry to hear you’re having issues. The
run_configstuff is still experimental (and undocumented), so thanks for trying things out. I believe all the issues you’re having have to do with your prefect/k8s configuration, and aren’t evidence of a bug in prefect/dask/something else. Responding inline:From the community slack, it looks like you’re used to using the
DaskKubernetesEnvironment, which runs your flow spread out across a number of k8s pods. Switching to usingKubernetesRunwill have your flow run using a single k8s pod (without additional executor configuration) - depending on your flow this may be fine or lead to perf issues. By default the flow will run serially, one task at a time, but (as you’ve rightly noted) you can set anexecutoron the flow to re-enable parallelism.Both options you’ve tried will run within the same pod using either threads or processes - but for this to be effective, the pod needs sufficient resources to run in parallel. For IO heavy tasks, using more threads than you have cores allocated to your pod is fine, but for compute heavy tasks you don’t want more processes/threads than you have cores (I’m not sure what your flow is doing, but it sounds like it’s compute heavy).
In the latest release (0.13.11) there are no default resource limits for a job, your job will be scheduled wherever the k8s cluster sees fit. In previous releases, the cpu request/limit were limited to < 0.1 cpu, which isn’t enough for any compute-heavy task. You can always set your own limit/request (as you’ve found) by passing
cpu_limit/cpu_requesttoKubernetesRun.Yeah, if you request a pod that requires more resources than any node in the cluster can give, it will hang until there’s a place for it (possibly forever). This depends on the node configurations of your system, and if you have any auto-scaling node pools. Running everything in a single pod is simpler, and is what I’d recommend when possible, but once your compute gets large enough it may be less expensive to scale out to multiple pods than require a larger cluster node be available.
From that configuration, I’d guess you’re swamping the node, as it doesn’t have enough cpu to manage that many workers. The flow would eventually run, but it would be so slow because everything is highly oversubscribed.
I believe the above explains the issues you’ve been seeing, please let me know if you have any questions.
I plan to write a bunch of example docs for deployments with run configs, and there will certainly be a large section on k8s (both with and without dask), but for now there’s unfortunately not anything I can point you to. To use dask-kubernetes without the
DaskKubernetesEnvironment, you’d want to configure yourDaskExecutorwith acluster_class/cluster_kwargs/adapt_kwargsto start and scale adask_kubernetes.KubeClusterappropriately.cluster_class: either the import name of a callable, or a callable to create a dask cluster. Ideally"dask_kubernetes.KubeCluster"would be all you’d need, but not all options you might want to change (like the worker images) are exposed in the constructor without writing k8s specs. This is unfortunate, I’m hoping to upstream some patches to make this easier to do.cluster_kwargs: kwargs to pass tocluster_classat runtime to create a cluster.adapt_kwargs: kwargs to pass tocluster.adaptat runtime to enable adaptive scaling, if desired.Ideally I’d like the following to work:
But
imageisn’t exposed in theKubeClusterconstructor, so you’d need to do something more like:(you might find the dask-kubernetes docs useful here).
Apologies that there aren’t better docs on this - as I said before you’re using some very new features. If you do try out the above, please let us know how things work for you.