
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
RaptorX: Unifying Hive-Connector and Raptor-Connector with Low Latency
See original GitHub issueThe feature has been general available and fully battled tested in Hive connector. Raptor connector is no longer maintained. Please use this feature instead.
Raptor is a sub-second latency query engine but has limited storage capacity; while Presto is a large-scale sub-min latency query engine. To take advantage of both engines, We propose “RaptorX”, which runs on top of HDFS like Presto but still provides sub-second latency like Raptor. The goal is to provide a unified, cheap, fast, and scalable solution to OLAP and interactive use cases.
Current Presto Design
- Presto uses compute servers. It directly connects to Hive Metastore as its metastore.
- The servers are stateless. A cluster directly reads data from HDFS. How data is maintained by HDFS or Hive Metastore is completely off the business from Presto.
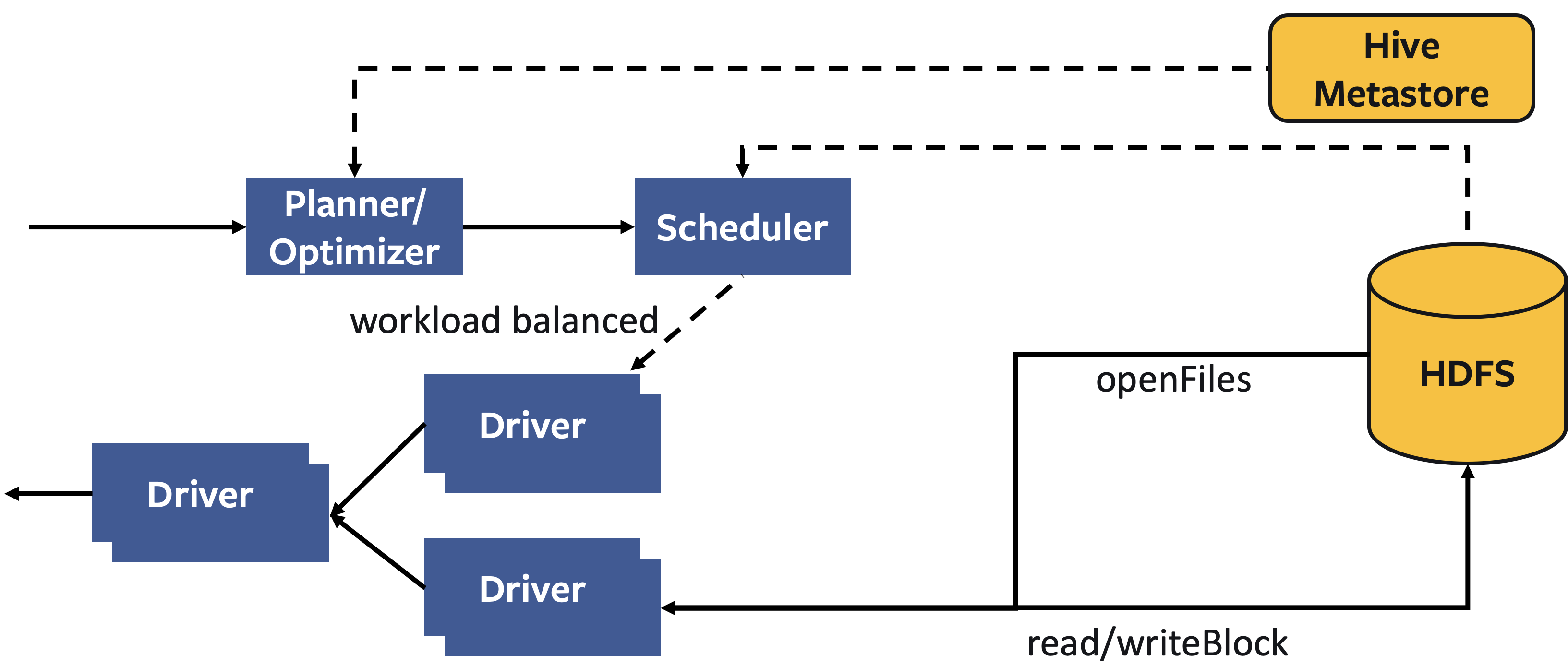
Current Raptor Design
- Raptor uses compute and storage combined servers. It usually needs a remote backup store and MySQL as its metastore.
- Users need to run batch jobs to load data from warehouse to Raptor clusters.
- Each Raptor worker has background jobs to maintain files (backup, compaction, sorting, deletion, etc).

Read/Write Path
- Page Source: ORC file stream reader for file reading
- Page Sink: ORC file stream writer for file writing
Background Jobs
- Compaction and Cleaning (with data sorting as an option): ShardCompactor to merge small files into large ones to avoid file reading overhead.
- Create a single “Page Sink” with multiple “Page Sources”. Read multiple ORC files and flush into a single one.
- ShardCleaner to garbage collect files that have been marked as deleted.
- Backup: Backup store for creating backup files in remote key-value store and restore backup file when necessary
Metadata
- Raptor Metadata: a wrapper on several MySQL clients given all metadata is stored in MySQL.
- Schema: save all the metadata at table level including schemas, tables, views, data properties (sorting, bucketing, ), table stats, bucket distribution, etc.
- Stats: save all the metata at file level including nodes, transaction, buckets, etc.
Pros and Cons with Current Raptor/Presto
| Presto | Raptor – | – | – Pros | Large-scale storage (EB) | Low latency (sub-second) Pros | Independent storage and compute scale | Refined metastore (file-level) Cons | High latency (sub-minute) | Mid-scale storage (PB) Cons | Coarse metastore (partition-level) | Coupled storage and compute
RaptorX Design
“RaptorX” is a project code name. It aims to evolve Presto (presto-hive) in a way to unify presto-raptor and presto-hive. To make sure taking the pros from both Presto and Raptor, we made the following design decisions:
- Use HDFS for large-scale storage (EB) and independent storage and compute scale Use hierarchical cache to achieve low latency (sub-second)
- Inherit and refine the existing Raptor metastore for file pruning and scheduling decision making
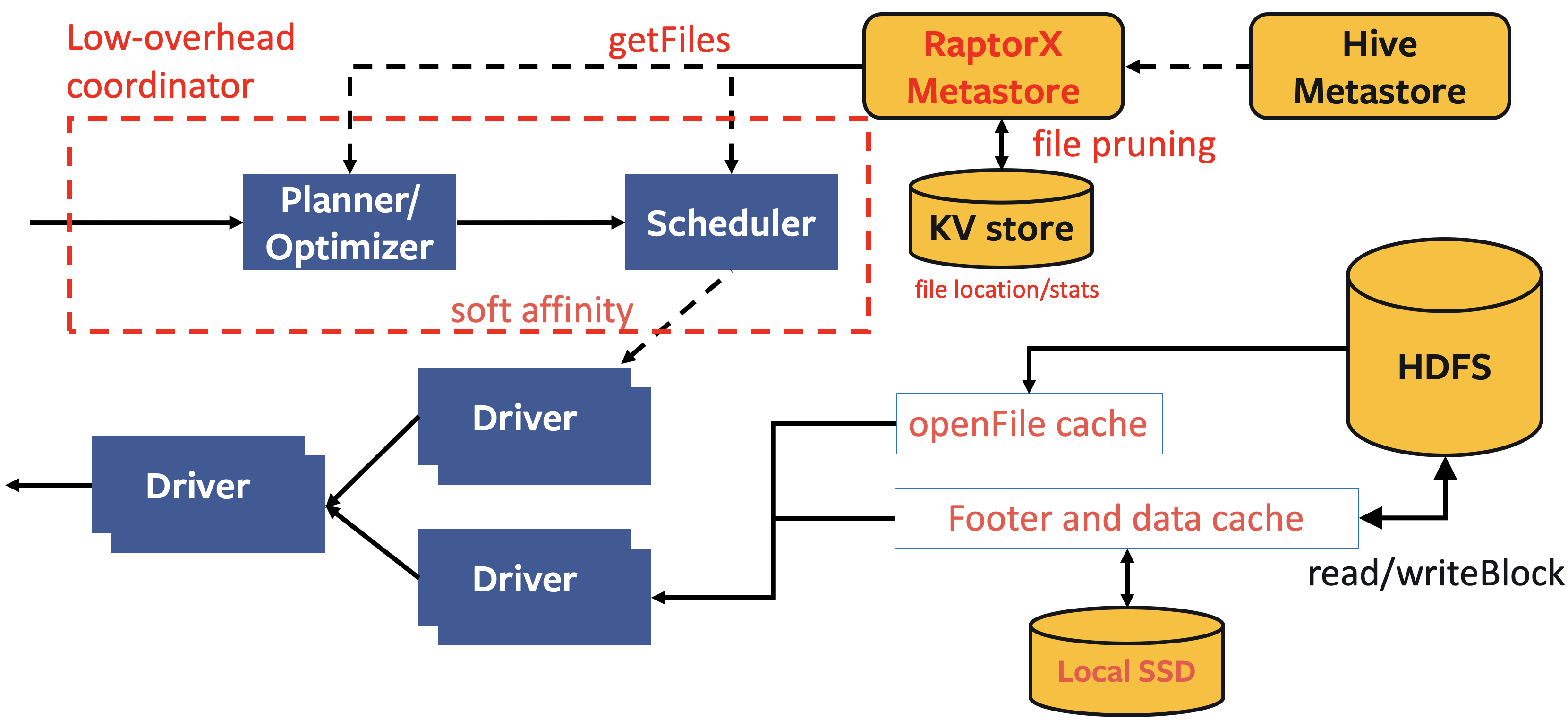
Read/Write Path
- Page Source/Sink: migrate file system from local FS to WS and HDFS environment, where WS is for FB and HDFS is for open source.
- Hierarchical Cache: check the following “Cache” bullet.
Cache
- Worker cache
- File handle caching: avoid file open calls
- File/stripe footer caching: avoid multiple redundant RPC calls to HDFS/WS
- In-memory data caching: async IO + prefetch
- Local data cache on SSD: avoid network or HDFS/WS latency.
- Coordinator cache
- File stats for pruning
- ACL checks
- Parametric query plans
Background Jobs
- Completely remove: users can use Spark or Presto to write sorted and compacted data. WS will take care of fault tolerance. This will provide immutable partitions for Raptor that will be able to have free WH DR and privacy
Metastore
- Hive Metastore compatibility: Hive Metastore will be the source of truth. RaptorX will keep a refined copy of Hive Metastore containing file-level stats for pruning and scheduling.
- Raptor Metastore: the enriched metastore.
- Detach worker assignment from metastore. Metastore should not have ties with worker topology.
- Raptor Metastore is a richer metastore contains file-level stats that can be used for range/z-order partitioning
- Metastore protocol
- RaptorX calls Hive Metastore for every query
- Hive Metastore provides a hash/digest to indicate the version number of a partition. A digest indicates if the content has been changed for a partition due to backfill, NRT, etc
- If the digest matches the Raptor Metastore one, use the Raptor Metastore; otherwise fall back to Hive Metastore
- If a user chooses to ingest data with RaptorX, file-level stats + partition info will be kept in Raptor Metatore and partition info will be published to Hive Metastore.
Coordinator
- Soft affinity scheduling:
- The same worker should pull data from the chunk server to leverage FS cache on chunk server.
- The scheduling should be “soft” affinity, meaning that it should still take workload balancing into consideration to avoid scheduling skew. The current Raptor scheduling is “hard” affinity that can cause some workers to pull more data than others causing long-tail issues.
- Low-latency overhead:
- Reduce coordinator parsing, planning, optimizing, ACL checking overhead to less than 100ms.
Interactive query flow
- Presto coordinator receives a user query and sends a request to RaptorX metastore with the table name, partition values, constraints from the filter, user info (for ACL check), etc.
- RaptorX metastore checks its in-memory table schema and ACL cache for basic info. If there is a cache miss, it asks Hive metastore for them.
- RaptorX metastore checks its in-memory cache if it contains the required table name + partition value pair
- If it contains the pair, RaptorX metastore sends the version number to the KV store to see if that is the latest version. If it is the latest version, RaptorX metastore prunes files based on the given constraints.
- If it does not contain the pair, fetch it from the KV store and repeat the above step. RaptorX returns the schema, file locations, etc back to Presto coordinator.
Production Benchmark Result

Milestones and Tasks
How to Use
Enable the following configs in Hive connector (with the exception that fragment result cache is for main engine)
Scheduling (/catalog/hive.properties):
hive.node-selection-strategy=SOFT_AFFINITY
Metastore versioned cache (/catalog/hive.properties):
hive.partition-versioning-enabled=true
hive.metastore-cache-scope=PARTITION
hive.metastore-cache-ttl=2d
hive.metastore-refresh-interval=3d
hive.metastore-cache-maximum-size=10000000
List files cache (/catalog/hive.properties):
hive.file-status-cache-expire-time=24h
hive.file-status-cache-size=100000000
hive.file-status-cache-tables=*
Data cache (/catalog/hive.properties):
cache.enabled=true
cache.base-directory=file:///mnt/flash/data
cache.type=ALLUXIO
cache.alluxio.max-cache-size=1600GB
Fragment result cache (/config.properties and /catalog/hive.properties):
fragment-result-cache.enabled=true
fragment-result-cache.max-cached-entries=1000000
fragment-result-cache.base-directory=file:///mnt/flash/fragment
fragment-result-cache.cache-ttl=24h
hive.partition-statistics-based-optimization-enabled=true
File and stripe footer cache (/catalog/hive.properties):
--- for orc:
hive.orc.file-tail-cache-enabled=true
hive.orc.file-tail-cache-size=100MB
hive.orc.file-tail-cache-ttl-since-last-access=6h
hive.orc.stripe-metadata-cache-enabled=true
hive.orc.stripe-footer-cache-size=100MB
hive.orc.stripe-footer-cache-ttl-since-last-access=6h
hive.orc.stripe-stream-cache-size=300MB
hive.orc.stripe-stream-cache-ttl-since-last-access=6h
-- for parquet:
hive.parquet.metadata-cache-enabled=true
hive.parquet.metadata-cache-size=100MB
hive.parquet.metadata-cache-ttl-since-last-access=6h
Issue Analytics
- State:

- Created 4 years ago
- Reactions:8
- Comments:23 (16 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
@teejteej, yes the feature is fully available and battled tested. Here are the configs to enable for hive connectors:
Scheduling (/catalog/hive.properties):
Metastore versioned cache (/catalog/hive.properties):
List files cache (/catalog/hive.properties):
Data cache (/catalog/hive.properties):
Fragment result cache (/config.properties):
Adding to what @highker said, there are also knobs for file/stripe footer cache for ORC and Parquet files as shown below. Note that in Facebook’s deployment (we use ORC), we found it would increase GC pressure so it is disabled, but I think it is still worthwhile to point this feature out just for visibility as it might work for different workload.
@ClarenceThreepwood might have a better idea about how Parquet metadata cache works in Uber.
ORC:
Parquet: