
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
`findOne` optimization
See original GitHub issueTo quote from an earlier specs issue:
One of the main usecases of
PhotonPrisma Client is to use it inside a GraphQL server. The resolver system of a GraphQL server is prone to suffer from the N+1 problem. To mitigate this problem users can choose to implement the DataLoader pattern within the application server. This burdens our users with unnecessary work that is not related to their core domain. This issue explores how we could include a DataLoader implementation withinPhotonPrisma Client.
As a first step we want to look specifically into optimizing findOne queries by batching them.
Issue Analytics
- State:

- Created 4 years ago
- Reactions:5
- Comments:18 (11 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Memo: unsurprisingly faster with optimization.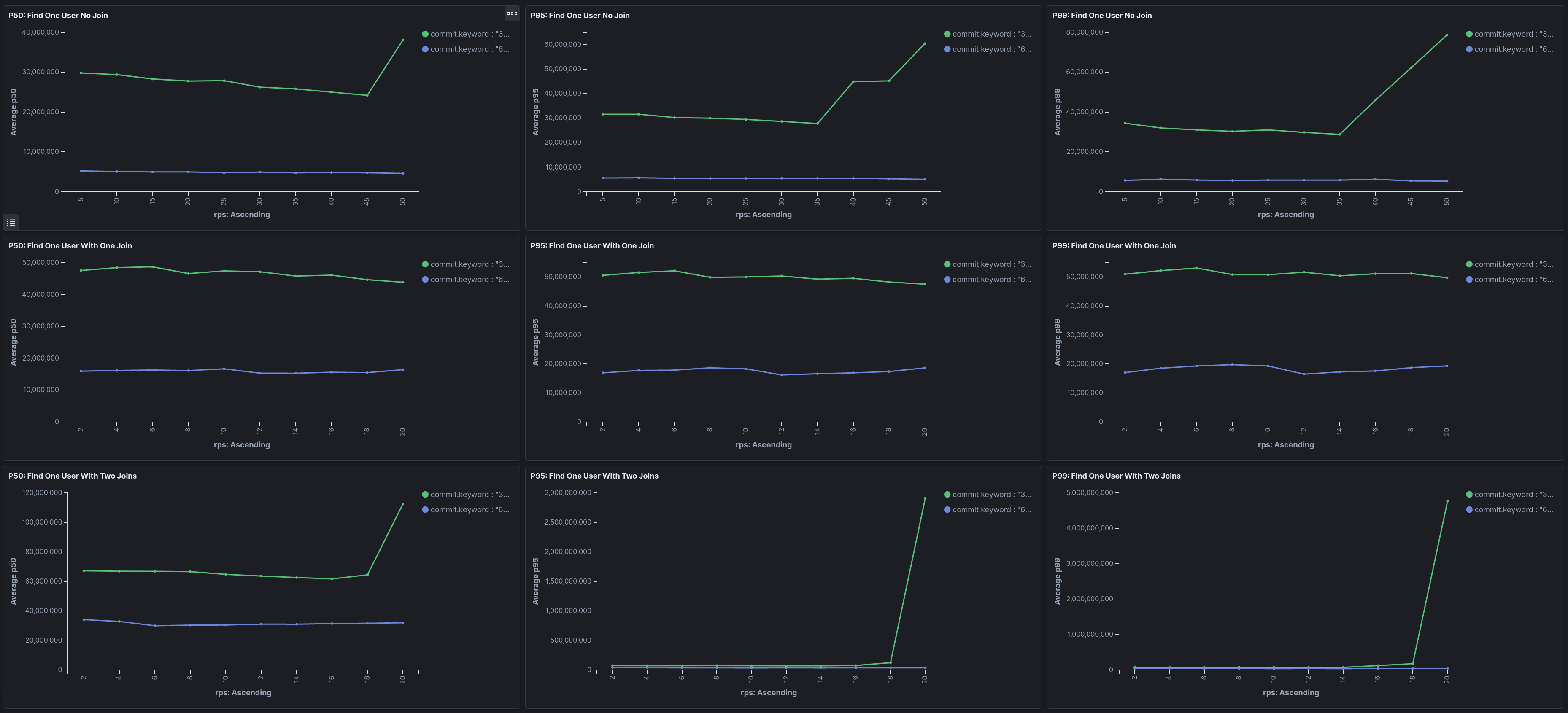 Green: batching without optimization
Purple: with optimization
Y: response time in nanoseconds
X: requests per second
Green: batching without optimization
Purple: with optimization
Y: response time in nanoseconds
X: requests per second
Tested three queries in batches of 100,
$user_idrandomized from 1 to 3000. 3000 users, 30000 posts and 30000 comments.@mavilein We didn’t really solve it, we just added timings just before and just after resolvers to see how fast queries were resolved.
I do agree that it’s a hefty query. But production workloads are gonna go way beyond this I think 😄 The N+1 is definitely the big slowdown in this case, the worst thing about the N+1 is probably the overhead it takes for every query to resolve and go back and forth between Prisma-client and the database. (Which both run on localhost, so also shouldn’t be an issue, deployed on GCP both running in Cloud Run we have similar timings)
My example is also a findMany on activities, I don’t think a findOne would be as bad as a findMany. Think batching would be much more usefull in findMany than a findOne. But then again, the logic from findOne would probably be reuseable in de findMany
I don’t mind open ended comments, performance surely isn’t as straightforward as it seems!