
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
page.evaluate() is leaking memory
See original GitHub issueSteps to reproduce
Tell us about your environment:
- Puppeteer version: 1.12.2
- Platform / OS version: Ubuntu 18.04.2
- URLs (if applicable): https://www.gofundme.com/cross-country-bike-trip
- Node.js version: 10.15.1
What steps will reproduce the problem?
I am using Puppeteer to scrape data from tens of thousands of URLs which are listed in a file. After a few hundred URLs, my program always crashes with this error:
Error: Failed to scrape URL https://www.gofundme.com/cross-country-bike-trip: TimeoutError: Navigation Timeout Exceeded: 30000ms exceeded at Promise.then (/var/www/scraper/node_modules/puppeteer/lib/LifecycleWatcher.js:143:21) -- ASYNC -- at Frame. (/var/www/scraper/node_modules/puppeteer/lib/helper.js:108:27) at Page.goto (/var/www/scraper/node_modules/puppeteer/lib/Page.js:662:49) at Page. (/var/www/scraper/node_modules/puppeteer/lib/helper.js:109:23) at scanURLs (/var/www/scraper/middleware/scan-urls.js:30:33) at process._tickCallback (internal/process/next_tick.js:68:7) at scanURLs (/var/www/scraper/middleware/scan-urls.js:205:13)
If I restart the program, it always picks up where it left off and scrapes the URL just fine… so I know it is not this particular URL that is the issue.
What is the expected result?
Since it scraped hundreds of URLs just fine, and there doesn’t appear to be anything special about this URL, and it scrapes this URL just fine when I restart the program, I would expect it to scrape this URL (and all other URLs) without any issues.
What happens instead?
The program crashes with the above error.
My code
It is very long, but I will include what I believe are the relevant parts here:
index.js:
require('dotenv').config()
const fs = require('fs')
const error = require('./middleware/error')
const mongoose = require('mongoose')
const puppeteer = require('puppeteer')
const Marker = require('./models/marker')
const scanSubmaps = require('./middleware/scan-submaps');
(async () => {
// connect to the database
await mongoose.connect(
'mongodb://' + process.env.MONGO_USER_DEV + ':' + process.env.MONGO_PW_DEV + '@' + process.env.MONGO_IP_DEV + ':' + process.env.MONGO_PORT_DEV + '/' + process.env.MONGO_DB_DEV,
{
useNewUrlParser: true
}
)
// initiate page
let page = null
const browser = await puppeteer.launch({
headless: true,
args: ['--full-memory-crash-report']
})
page = await browser.newPage()
await page.setViewport({ width: 1366, height: 768 })
await page.setRequestInterception(true)
// don't download unnecessary resources
page.on('request', (req) => {
if(req.resourceType() === 'image' || req.resourceType() === 'stylesheet' || req.resourceType() === 'font'){
req.abort()
} else {
req.continue()
}
})
// get markers from database
let markers = await Promise.all([
Marker.findOne({ name: 'submap' })
.select('value')
.exec(),
Marker.findOne({ name: 'url' })
.select('value')
.exec()
])
let submapMarker = markers[0]
let urlMarker = markers[1]
// if no submap marker
if (submapMarker == null) {
// set submap marker to 0
submapMarker = 0
// else, set to its value
} else {
submapMarker = submapMarker.value
}
// if no URL marker
if (urlMarker == null) {
// set URL marker to 0
urlMarker = 0
// else, set to its value
} else {
urlMarker = urlMarker.value
}
// get list of submaps from sitemap
let sitemap = fs.readFileSync('./sitemaps/sitemap.xml')
let submapList = String(sitemap).match(/<loc>([^<]+)<\/loc>/g)
// scan submaps (starting at submap marker)
await scanSubmaps(page, submapList, submapMarker, urlMarker)
// delete all markers
await Marker.deleteMany({})
.exec()
})().catch(err => {
await mongoose.disconnect()
if (typeof page !== 'undefined') {
await page.close()
}
if (typeof browser !== 'undefined') {
await browser.close()
}
error(err)
})
scan-submaps.js:
const Marker = require('../models/marker')
const fs = require('fs')
const scanURLs = require('./scan-urls')
module.exports = async function scanSubmaps(page, submapList, submapMarker, urlMarker) {
// slice submapList
submapList = submapList.slice(submapMarker)
// for each submap
for (const item of submapList) {
// get submap name
let submapName = item.match(/sitemap[0-9a-z_]+\.xml/)
// get list of URLs from submap
let submapContents = fs.readFileSync('./sitemaps/' + submapName)
let urlList = String(submapContents).match(/<url>(.+?)<\/url>/g)
// scan URLs (starting at URL marker)
await scanURLs(page, urlList, urlMarker, submapMarker)
// increment submap marker
submapMarker++
await Marker.findOneAndUpdate({ name: 'submap' }, { value: submapMarker }, { upsert: true })
.exec()
// reset URL marker
urlMarker = 0
await Marker.findOneAndUpdate({ name: 'url' }, { value: 0 })
.exec()
}
// scan complete
return 'Submaps scanned successfully.'
}
scan-urls.js:
const Entry = require('../models/entry')
const Marker = require('../models/marker')
module.exports = async function scanURLs(page, urlList, urlMarker, submapMarker) {
// slice urlList
urlList = urlList.slice(urlMarker)
// for each URL
for (const item of urlList) {
// get URL
let url = item.match(/<loc>([^<]+)<\/loc>/)[1]
try {
// load URL
let response = await page.goto(url)
// if redirect, skip URL
let redirects = response.request().redirectChain()
if (redirects.length > 0) {
// skip URL
} else {
// scrape page content
let scraped = await page.evaluate(() => {
// SCRAPE A BUNCH OF DATA
// return scraped data
return {
data1: data1,
data2: data2,
data3: data3,
etc: etc
}
})
let entry = {
url: url,
data1: scraped.data1,
data2: scraped.data2,
data3: scraped.data3,
etc: scraped.etc
}
// add/update database entry
await Entry.findOneAndUpdate(
{ url: url },
entry,
{ upsert: true }
)
.exec()
}
// increment URL marker
urlMarker++
await Marker.findOneAndUpdate({ name: 'url' }, { value: urlMarker }, { upsert: true })
.exec()
// log URL if error
} catch (err) {
throw new Error('Failed to scrape URL ' + url + ': ' + err.stack)
}
}
// scan complete
return 'URLs scraped successfully.'
}
Issue Analytics
- State:

- Created 5 years ago
- Comments:26 (3 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
I have the same problem in Puppeteer 8.0.0. Evaluate function is kept in memory as strings.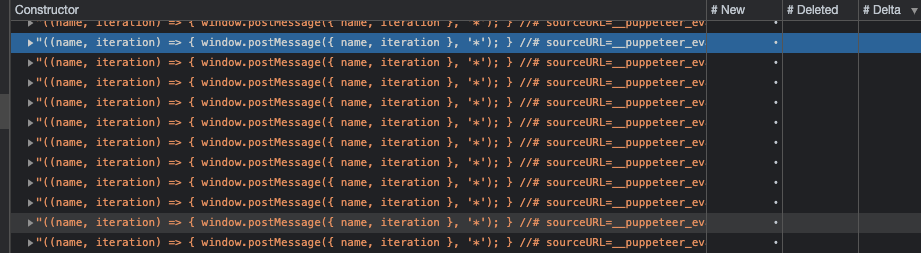
I run page.evaluate a lot of times. How to disable debugger to prevent that strange behavior?
Hi @falkenbach, the example I posted was only demonstrating what had actually caused my memory leak, but I had been using page.evaluate in my own project at the time I wrote the initial post. In hindsight, it would have been better to post the example somewhere else, so I’ve removed the comment and example. Thanks!