
Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Text not in the expected cell
See original GitHub issueHere is my document:
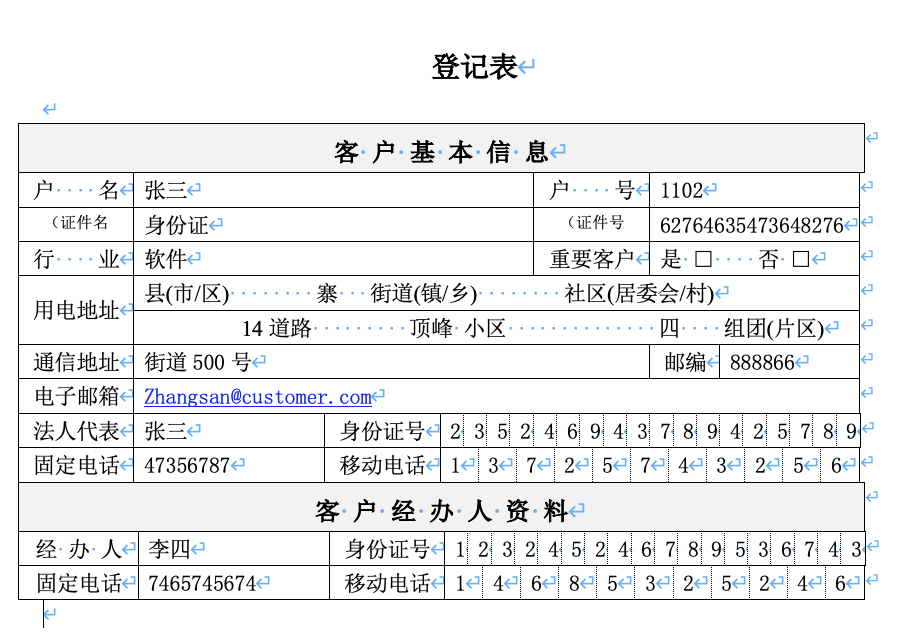
I want to extract tuples like("户名", "张三"),("户号", "1102"), but I found I cannot locate values correctly using the following code:
from docx import Document
file = '/paht/to/my_doc.docx'
doc = Document(file)
tables = doc.tables
table = tables[0] # now, I get the table object successfully
# Intuitively, "户 名" is in the first cell of second row. When I try to find it:
row_num = 1
cell_num = 0
row = table.rows[row_num]
cell = row.cells[cell_num]
print(cell.text) # will print "张三"
# Actually,"户 名" is in the last cell of first row:
row_num = 0
row = table.rows[row_num]
cell = row.cells[-1]
print(cell.text) # will print "户 名"
Could anybody please tell me what’s wrong with it:)
Issue Analytics
- State:

- Created 2 years ago
- Reactions:1
- Comments:9 (4 by maintainers)
 Top Results From Across the Web
Top Results From Across the Web
Fix text-formatted numbers by applying a number format
Numbers that are formatted as text are left-aligned instead of right-aligned in the cell, and are often marked with an error indicator. What...
Read more >Observed Values less than 5 in a Chi Square test - No biggie.
The assumption of the Chi-square test is not that the observed value in each cell is greater than 5. It is that the...
Read more >Excel: If cell contains formula examples - Ablebits
Finding cells containing certain text (or numbers or dates) is easy. You write a regular IF formula that checks whether a target cell...
Read more >ACE OLEDB "External table is not in the expected format" with ...
I'm trying to read an .xls file that happens to have a very large text cell (around 8900 chars) using System.Data.OleDb and the...
Read more >8. The Chi squared tests - The BMJ
To calculate the expected number for each cell of the table consider the null ... or if the total lies between 20 and...
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
Okay, in the XML you sent me,
w:tbl/w:tblGridcontains 32w:gridColentries. This means the table layout grid is 32 columns wide.The first row (the long merged heading) only accounts for 31 layout grid columns. I think that’s the source of the problem and
python-docxis interpreting the first cell of the second row as the 32nd cell in the first column.Basically, the table is just too complex for
python-docxto navigate it. There are rules that Word has for rendering tables that go beyond the simple-ish uniform layout-grid concept and that are not implemented inpython-docx. So pursuing the “row-by-row” “apparent-cell” approach we mentioned above is probably the best course.@zifeiYv ok, that all looks in order, I suspect that the table is not consistent with the spec and its underlying layout-grid is corrupted, which means the
python-docxcell addressing won’t work reliably. There is a lot of merging of cells in that table and it can happen that Word can still render the table but the layout-grid addressing ofpython-docxcan’t figure out which cell is which.Can you dump the overall table to an XML file and attach it? (
print(table._element.xml)it will be too long to paste into a comment-box here)But whatever we find out there, I think the best available path is for you to resort to “physical” indexing:
The cells accessed this way should work just as well as any other cell and will be much easier to address in a complex layout like this.