
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Error with Models using both float and long as input
See original GitHub issue❓ Question
I was trying captum on tab transformer, trying to find which features affect the result by using integrated_graditents. As seen in the picture of the readme file, it accepts two inputs:
- Categorical features (which is of type
torch.longor similar) - Continious features (which is of type
torch.float)
Inside the model, the categorical features are passed through the embedding layer before further operations, converting into torch.float.
When running integrated_gradients.attribute, the categorical features are converted into torch.float before passing into forward method, giving error.
Note: Please note that this is different from a text classification model (where whole input is torch.long) or image classification model (where whole input is torch.float).
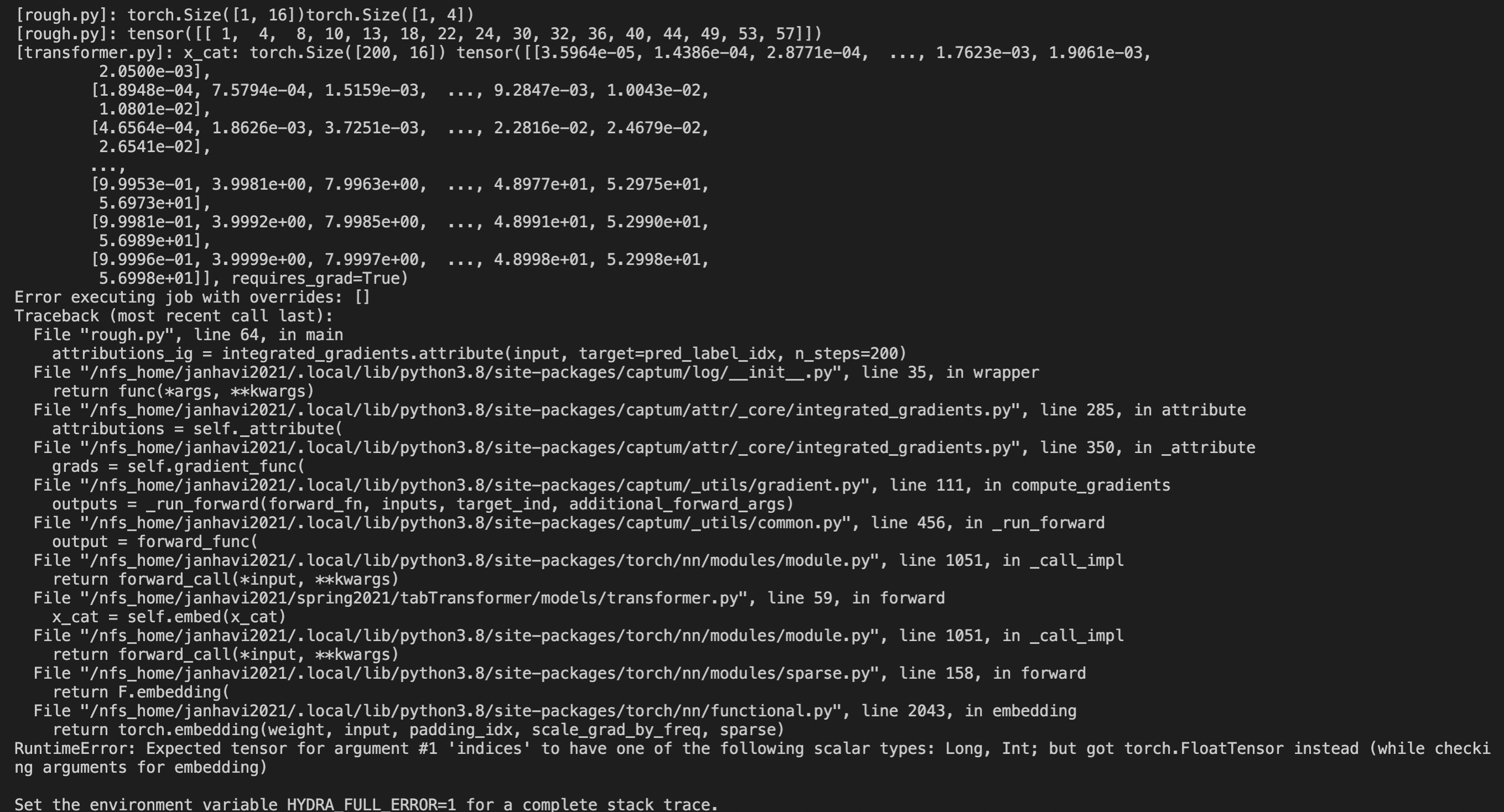
Attached below is screenshot of error, where I debug the passed tensor by printing it before the forward method of transformer
def forward(self, x_cat, x_cont):
batch_size, num_cat_cols = x_cat.shape
print(f'[transformer.py]: x_cat: {x_cat.shape} {x_cat}')
# x_cat.shape: (num_cat_cols, embed_dim)
x_cat = self.embed(x_cat)
And this is the contents of rough.py used to run integrated graditents calculation (python3 rough.py)
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, Dataset
from torch.optim import Adam
from tqdm import tqdm
from pprint import pprint
import wandb
import hydra
import logging
import pathlib
from models.transformer import TabTransformer
from data_loader.datasets import BlastcharDataset
from utils.utils import Phase
from captum.attr import IntegratedGradients
from captum.attr import GradientShap
from captum.attr import Occlusion
from captum.attr import NoiseTunnel
from captum.attr import visualization as viz
logging.basicConfig(level=logging.ERROR)
@hydra.main(config_path="conf", config_name="config")
def main(cfg):
# wandb.config.update(dict(cfg))
# Initialize the dataset
blastchar_dataset = BlastcharDataset(cfg.dataset.path)
NUM_CATEGORICAL_COLS = blastchar_dataset.num_categorical_cols
NUM_CONTINIOUS_COLS = blastchar_dataset.num_continious_cols
EMBED_DIM = 32
# initialize the model with its arguments
mlp = nn.Sequential(
nn.Linear(NUM_CATEGORICAL_COLS * EMBED_DIM + NUM_CONTINIOUS_COLS, 50),
nn.ReLU(),
nn.BatchNorm1d(50),
nn.Dropout(cfg.params.dropout),
nn.Linear(50, 20),
nn.ReLU(),
nn.BatchNorm1d(20),
nn.Dropout(cfg.params.dropout),
nn.Linear(20, blastchar_dataset.num_classes)
)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = TabTransformer(blastchar_dataset.num_categories, mlp, embed_dim=EMBED_DIM).to(device)
# model.load_state_dict(torch.load('/nfs_home/janhavi2021/spring2021/tabTransformer/saved/models/400epochs.pth'))
pred_label_idx = 0
# input = blastchar_dataset[0].squeeze(0)
cat, cont, _ = blastchar_dataset[0]
cat, cont = cat.unsqueeze(0).long(), cont.unsqueeze(0).long()
# input = torch.cat((cat, cont), dim=0)
input = (cat, cont)
print(f' \n\n\n[rough.py]: {cat.shape}{cont.shape}')
print(f'[rough.py]: {cat}')
integrated_gradients = IntegratedGradients(model)
attributions_ig = integrated_gradients.attribute(input, target=pred_label_idx, n_steps=200)
print(attributions_ig)
main()
To Reproduce
Steps to reproduce the behavior:
- Set up the tab transformers repo (either setup Balstchar dataset or generate the inputs of required shape and datatype: x_cat: 16 integers converted to
torch.long, x_cont: 4 floats converted totorch.floatas shown by first print line in the screenshot) - Try to run the integrated gradients code (the contents of which is shown in
rough.pygiven above)
Expected behavior
It should give the attributes of shape 20 (16 + 4) describing which feature (from the categorical and continious features) affects the result most.
Environment
Describe the environment used for Captum
- Captum / PyTorch Version (e.g., 1.0 / 0.4.0): captum==0.4.1, torch ‘1.9.0+cu102’
- OS (e.g., Linux): linux
- How you installed Captum / PyTorch (
conda,pip, source): pip install captum - Build command you used (if compiling from source):
- Python version: Python 3.8.8
- CUDA/cuDNN version:
- GPU models and configuration: N/A
- Any other relevant information:
Additional context
I went through the codebase, and it seems this line is converting the categorical features to torch.float (alpha being a float). Let me know if there is any alternate way to calculate the attributions for this case using captum.
Issue Analytics
- State:

- Created 2 years ago
- Comments:5 (2 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post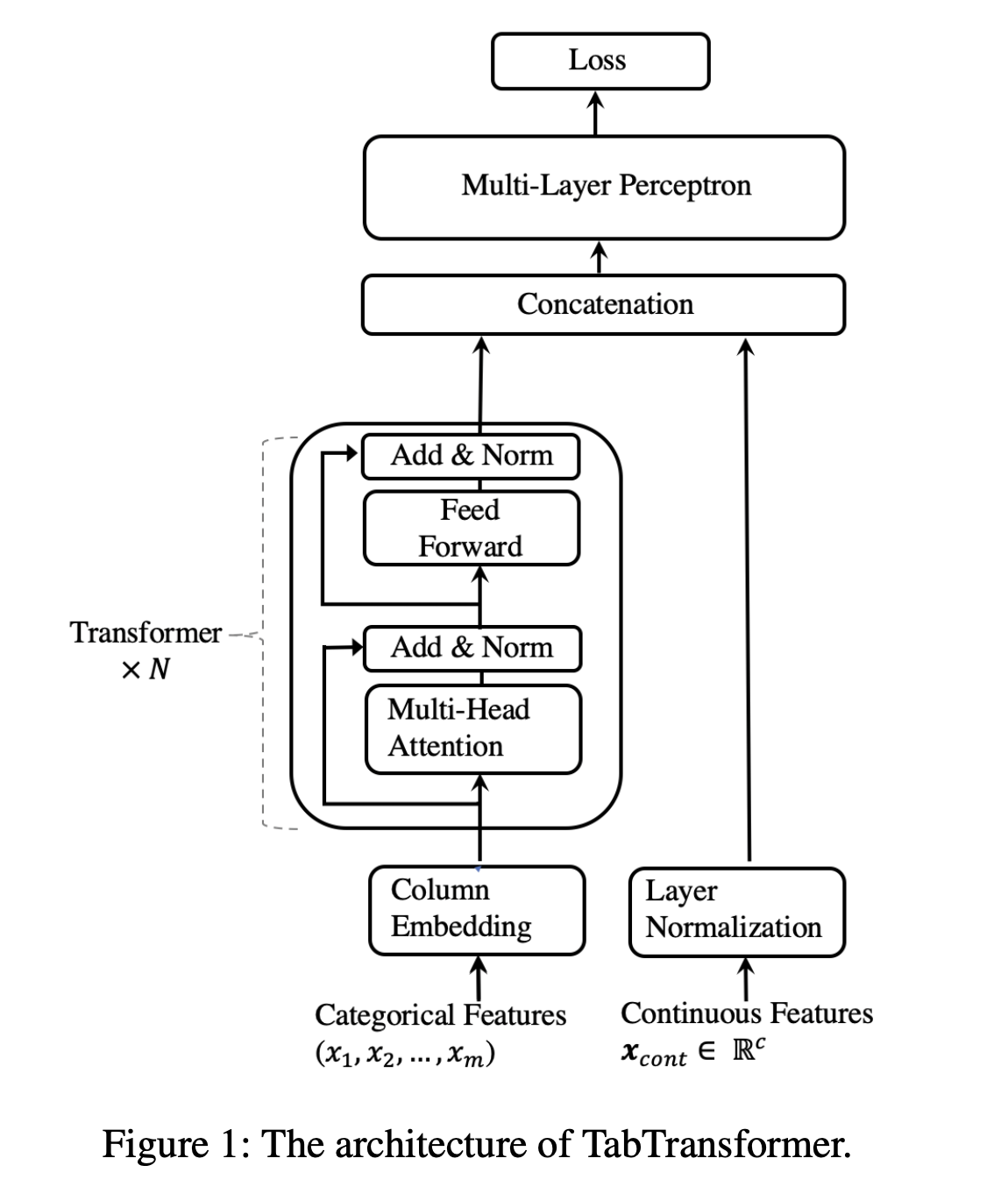{kind=link}
Hi @harshraj22 ,
your solution to pass multiple layers is the same
.attribute()call is even better. Now I understand your concern about the comparability of the computed attributions across modality. If you sum up the absolute attributions for all 16 categorical features, the sum will be comparable to that of all 4 scalar features, in the sense that you can estimate which modality has contributed more to the outcome. But I agree it might be less informative to compare the attributions of two individual features having different modality.Hope this helps
Hi @harshraj22 ,
I am very happy you figured out an excellent solution to get the attributions for the categorical features.
In your 1st post you also correctly identified the challenge of using
IntegratedGradientsto handle a mixed scalar + categorical input. Some solutions:IntegratedGradientsrelies on such interpolation. You can try using simple perturbation-based algorithms such asFeatureAblationandOcclusionor simplified gradient-based algorithms such asGuidedBackpropandLRP.IntegratedGradientstwice: Once for the 16 categorical features as you did, and once for the scalar features. You can try applyingrequires_grad=Falseto thecattensor to exclude it from the attribution, or define a wrapper that takes only the continuous features as an input and feeds the categorical features subsequently. That way, Captum won’t perform interpolation with the baseline that caused the error as you identified.Hope this helps