
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Relationship between LayerIntegratedGradients & configure_interpretable_embedding_layer
See original GitHub issueHi, I am working with the tutorial here. I took the example
question, text = “What is important to us?”, “It is important to us to include, empower and support humans of all kinds.”
and tried to see the effect of the word “What” on the start position using
attributions_start_sum[1]
which is
tensor(0.3861, device=‘cuda:0’, dtype=torch.float64, grad_fn=<SelectBackward>) Then I ran the code to get the effect of word, token_type and position embeddings and the attributions look like
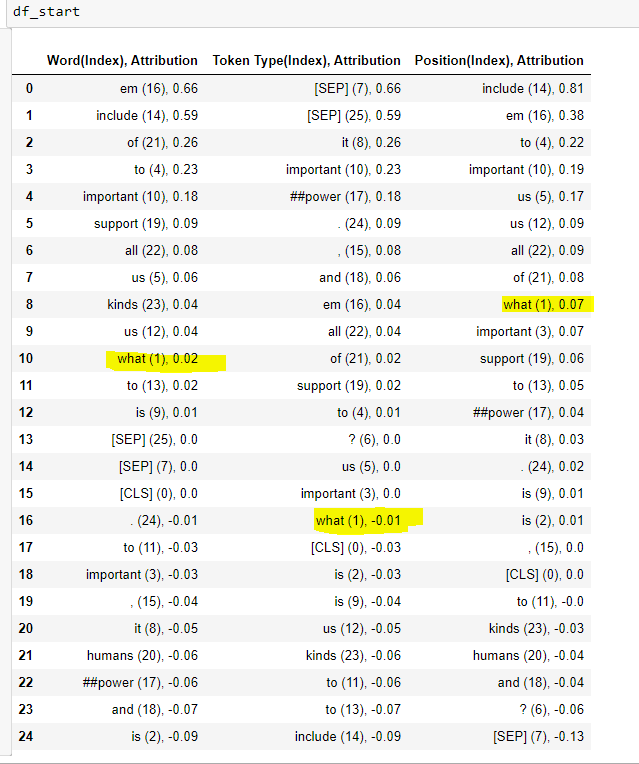
for “What”
0.02 + (-0.01) + 0.07 != 0.3861
Is this expected ? Could you please help me understand this
Issue Analytics
- State:

- Created 3 years ago
- Reactions:1
- Comments:6 (3 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
@LopezGG , I’d also look into LayerNorm and Dropout that is happening after concatenating those layers. https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_bert.py#L213
If you attribute to the inputs of the
LayerNormyou might get the result that you’re expecting ? Let me know if you get chance to try that.Not looking into this right now. thank you Narine