
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
What's the proper way to open parallel VTK files (*.pvtu)?
See original GitHub issueFirst thanks for this wonderful package! It is a much more sane way to manipulate VTK files in Python…
I wonder what’s the proper way to open parallel VTK files? It consists of a header file (*.pvtu) that points to normal VTK files (*.vtu). In ParaView, you can simply open the top-level *.pvtu file, and ParaView will automatically assemble the small VTK files into a single object.
Directly calling vtki.read('*.pvtu') leads to OSError: This file was not able to be automatically read by vtki.. So I open each small VTU file and use vtki.pointset.UnstructuredGrid.merge() to put them together. The full reproducible code is at https://github.com/JiaweiZhuang/vtk_experiments/blob/master/vtki_read_pvtu.ipynb, with small sample data files.
However, merge() seems to have problems at the boundaries between different subdomains:
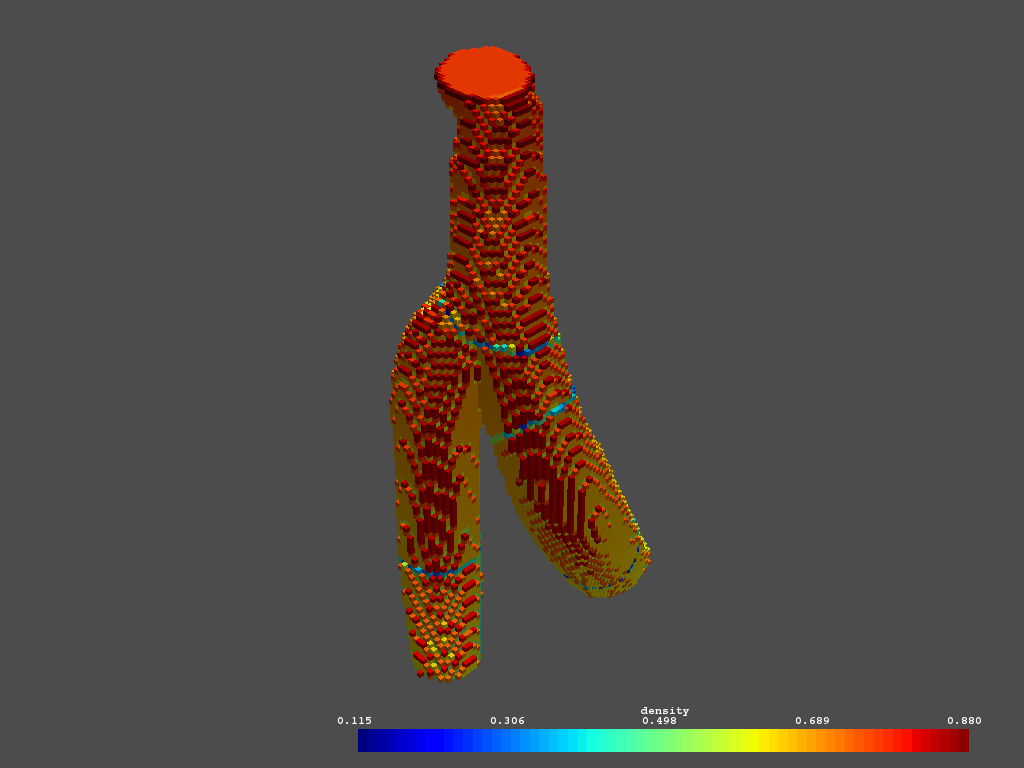
The blue/green lines are artifacts that shouldn’t exist in the original data. They correspond to the boundaries of domain-decomposition:

Here each color represents a VTK file.
Thus I wonder what’s the proper way to open and merge parallel VTK files? Would it be useful to add an API similar to Xarray’s open_mfdataset() to deal with multiple files?
Disclaimer: I have zero experience with VTK, but need to process some VTK files for a class project. Please forgive me if I miss anything obvious 😃
Issue Analytics
- State:

- Created 4 years ago
- Comments:8 (8 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
It’s now on the master branch and an example is live in docs: http://docs.vtki.org/examples/00-load/read-parallel.html
Yes I think that’s okay!