
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
[Bug] can't get ray cluster fully utilized
See original GitHub issueSearch before asking
- I searched the issues and found no similar issues.
(I created this issue based on a chat with Sang Cho)
Ray Component
Ray Clusters
What happened + What you expected to happen
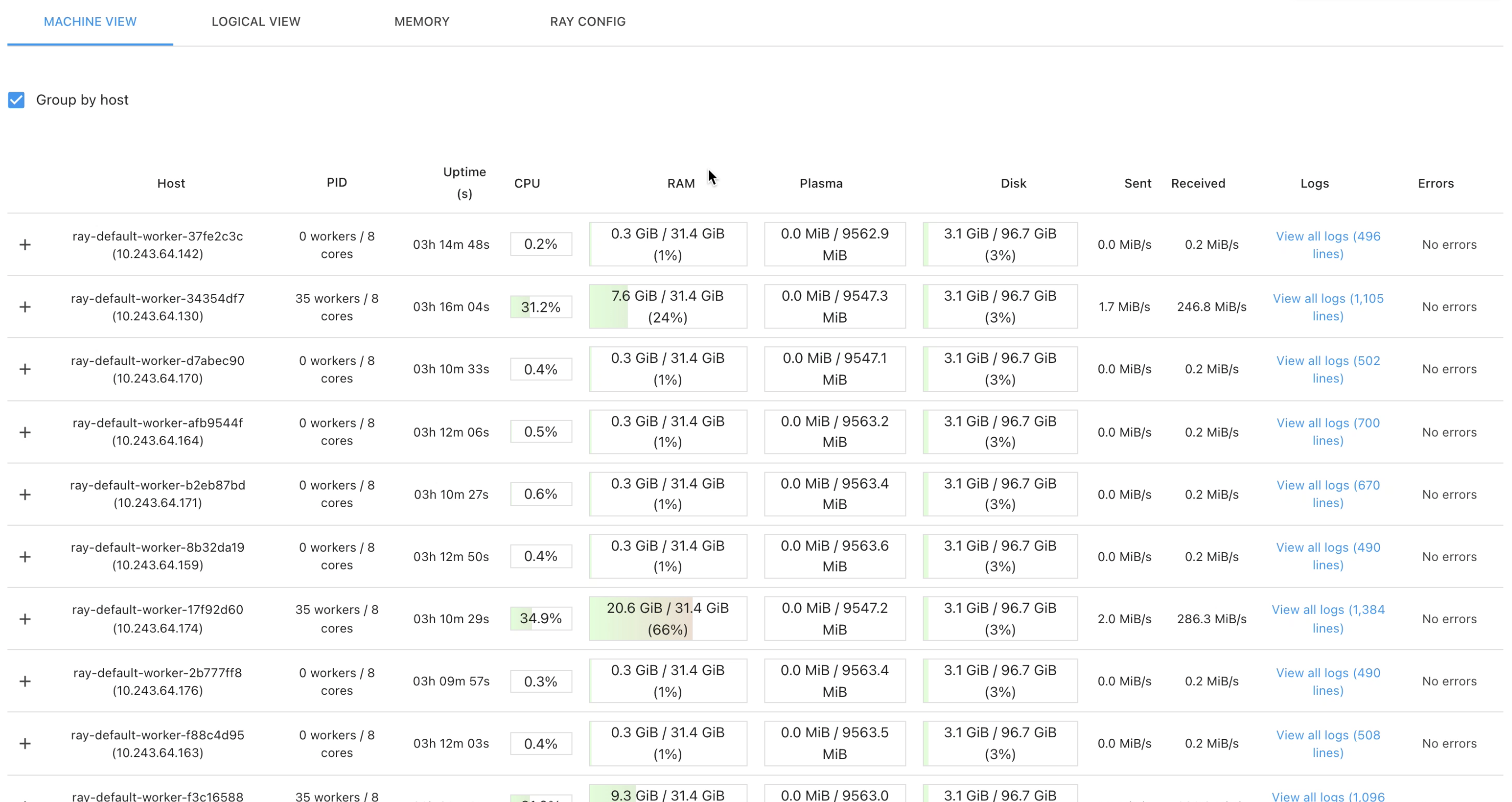
i created a cluster with 120 nodes, each having 8 vCPU and 32GB of memory. I triggered 10k task executions, and used the ray decorator assigning 0.15 vCPU to each task execution. While that should be enough work to fully utilize the cluster, many nodes are only lightly or not utilized at all (according to the ray dashboard).
Is this familiar behavior? Have you seen this in other scenarios of an equivalent size?
Versions / Dependencies
1.9
Reproduction script
I just call the task 10k times, which usually finished within a small, single-digit number of seconds. I also had tried the RAY_max_pending_lease_requests_per_scheduling_category == num_nodes environment variable setting, but didn’t see a major effect.
Anything else
No response
Are you willing to submit a PR?
- Yes I am willing to submit a PR!
Issue Analytics
- State:

- Created 2 years ago
- Comments:6 (4 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
we should tackle this at ray 2.1
the fundamental reason is ray single node scheduler becomes a bottleneck for embarrassingly parallel workload like this. An simple workaround for now is to submit jobs through actors placed on different nodes.