
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Channel inactive not fired after SslCloseCompletionEvent(SUCCESS) causing connection still in pool hence io.netty.handler.ssl.SslClosedEngineException: SSLEngine closed already
See original GitHub issueFrom time to time a connection is still in pool but should not.
Expected Behavior
SslCloseCompletionEvent(SUCCESS) not correctly handled is causing connection still present in pool hence “io.netty.handler.ssl.SslClosedEngineException: SSLEngine closed already” thrown on next usage of the connection. A Channel ‘INACTIVE’ shoud be fired after SslCloseCompletionEvent(SUCCESS)
Here is a fine example of a multi used (7 times) connection :
At the end, the connection is unregistered as soon as the sslCloseCompletion is fired :

Full logs : OK.log
Actual Behavior
In undetermined circumstances, SslCloseCompletionEvent is not followed by INACTIVE
In this example, the connection is reused 5min06 after SslCloseCompletionEvent
Contrary to what happened in “good” example above there is only one ‘READ COMPLETE’ event fired.
May be this is the reason why fireChannelInacctive is not triggered.

Full logs : NOK.log
Steps to Reproduce
Unfortunatly, I have no example to provide since this happen randomly.
Possible Solution
Bad idea, the SslReadHandler is not in the pipeline anymore when this happen.
In reactor.netty.tcp.SslProvider.SslReadHandler.userEventTriggered
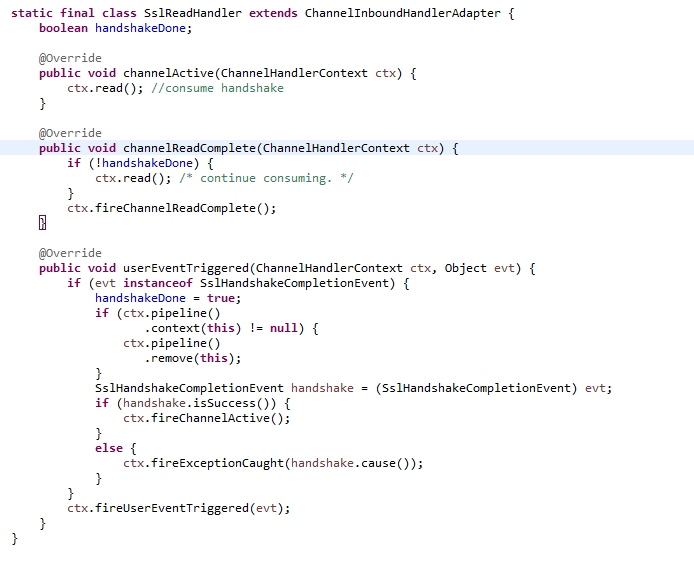
add
if (evt instanceof SslCloseCompletionEvent) {
ctx.fireChannelInactive();
}
Your Environment
- Reactor version(s) used: reactor-netty-http : 1.0.23
- Other relevant libraries versions (eg.
netty, …): netty : 4.1.81.Final - JVM version (
java -version): openjdk version “1.8.0_342” - OS and version (eg.
uname -a): Linux 18.04.1-Ubuntu SMP Mon Aug 23 23:07:49 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
Issue Analytics
- State:

- Created a year ago
- Comments:14 (7 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Glad to know my suggestion and proposed fix was quite good 😃
May I ask you when this fix is scheduled to be released ?Do not bother I found it :@cyfax,
some updates:
I’m still investigating, sorry for the bit of delay (please ignore my previous message for the moment, I’m still investigating).
So, based on the last NOK.1.log and from the tcpdump, let’s focus on the 48702 port. so, indeed, it seems that the client waits for the server FIN, which is not sent by the server after the initial close_notify, and at some point in time, when the client acquires and writes to the connection, then it gets the “SSLEngine closed already” exception, and the client then closes the connection.
let’s see this from your provided logs:
at 11:02:30.234595 from tcpdump: the server sends the close_notify to the client, which acknowledges it immediately:
From NOK.1.log, we see that the client has received the close_notify at 11:02:30.235
But after that, the server does not send a FIN to the client, even if this one has acknowledged the server close_notify with a client close_notify message (see at 11:02:30.235310)
And after 1,19 minute, at 11:03:49.680, the client then acquires the connection from the pool, writes to it, and is getting the “SslClosedEngineException: SSLEngine closed already”:
then, at 11:03:49.696, the client closes the connection:
and at 11:03:49.701184, from tcpdump, we then see that the FIN is sent from the client to the server:
so, first, it’s strange that the server is not closing the connection after having received the close_notify ack sent by the client.
now, we are still investigating, and after discussion with the team, we do not desire the do a patch for the moment, because closing the connection when receiving the close-notify will only resolve your particular scenario, but won’t avoid other scenarios where you have already acquired the connection: in this case, if the close_notify is received while you are writing to the acquired connection, then you will get a “Connection prematurely closed BEFORE response” even with the patch. Moreover, we are still investigating if something else could be done.
In the meantime:
Please consider to do what Violeta has suggested from this old issue, which seems to be the same problem: in the issue the problem was that the server was using a Keep-Alive timeout, and the server then sends a close_notify after some period of connection inactivity.
If you are using tomcat without any specific configuration, then Keep-Alive configuration is 60 sec if I’m correct (check https://github.com/reactor/reactor-netty/issues/1318#issuecomment-702619679). And indeed, from your tcpdump.txt, the server sends a close_notify after around 60 sec if inactivity:
So, please consider to use a maxIdleTime on the Reactor Netty’s connection pool to be less than the value on the server (check https://github.com/reactor/reactor-netty/issues/1318#issuecomment-702668918)