
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
[Redis Cluster] RedisTimeoutException: Unable to acquire connection! Increase connection pool size
See original GitHub issue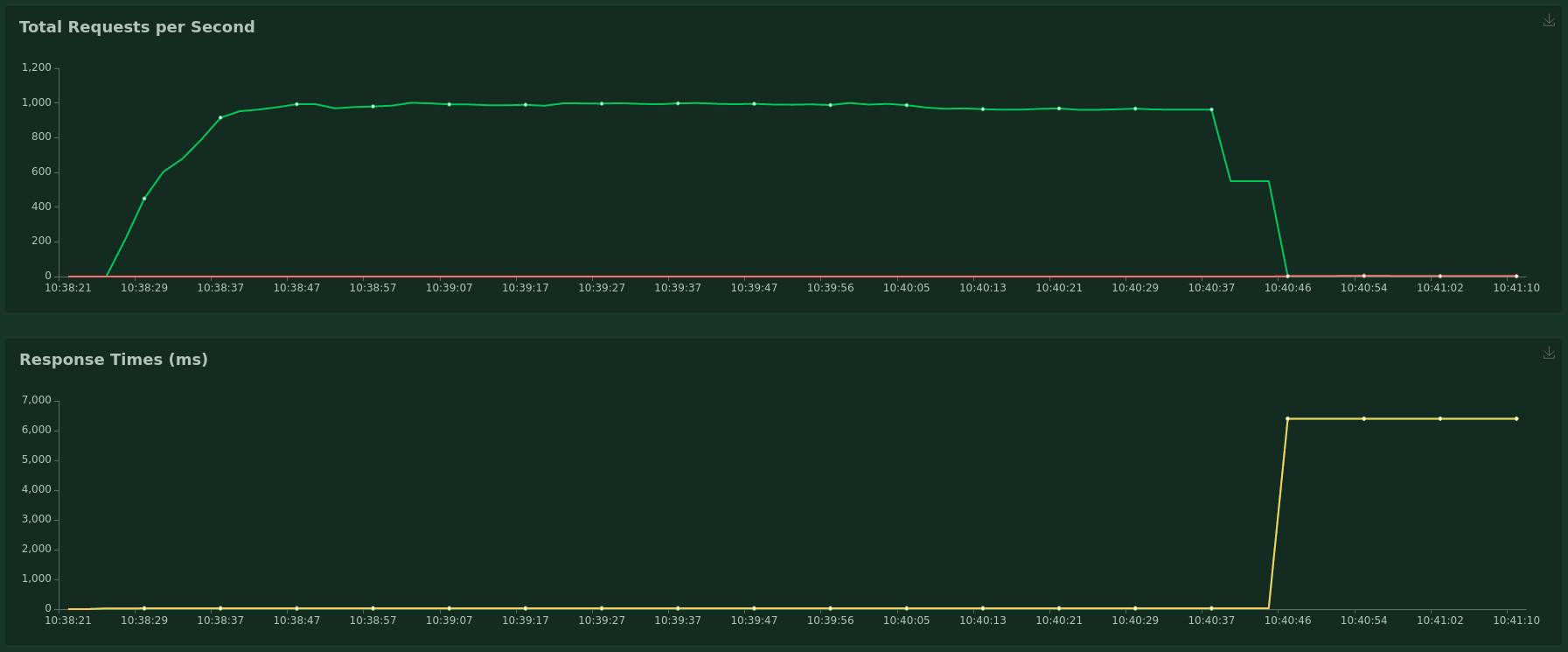
Expected behavior Redisson should not exhaust the connection pool. In other words, it should release connections after every successful command. And even if the pool is exhausted that should not make Redisson freeze completely until restarted I guess.
Actual behavior We have experienced this error in production and now I have managed to reproduce the error with a clean Spring Boot project and one endpoint that executes a lua script on a redis cluster. I am using Locust (locust.io) for load testing. More on how to reproduce the error later.
The screenshot shows an example Locust load test result: the first couple minutes are fine, I get around 1000 req per second and no errors. But then requests start to fail and response times go up to ~6 seconds. Sometimes it takes around 5 minutes as the test is a bit random.
This is the log for one of those failed requests:
2021-01-21 10:41:17.497 ERROR 11426 --- [nio-8080-exec-2] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is org.redisson.client.RedisTimeoutException: Unable to acquire connection! Increase connection pool size and/or retryInterval settings Node source: NodeSource [slot=0, addr=null, redisClient=null, redirect=null, entry=null], command: (EVAL), params: [local count
local ttl
count = redis.call("incr",KEYS[1])
ttl = redis.call("ttl",KEYS[1])
if tonumber..., 1, RATE_LIMIT_222.111.0.24, PooledUnsafeDirectByteBuf(ridx: 0, widx: 2, cap: 256)] after 0 retry attempts] with root cause
org.redisson.client.RedisTimeoutException: Unable to acquire connection! Increase connection pool size and/or retryInterval settings Node source: NodeSource [slot=0, addr=null, redisClient=null, redirect=null, entry=null], command: (EVAL), params: [local count
local ttl
count = redis.call("incr",KEYS[1])
ttl = redis.call("ttl",KEYS[1])
if tonumber..., 1, RATE_LIMIT_222.111.0.24, PooledUnsafeDirectByteBuf(ridx: 0, widx: 2, cap: 256)] after 0 retry attempts
at org.redisson.command.RedisExecutor$2.run(RedisExecutor.java:181) ~[redisson-3.14.1.jar:3.14.1]
at io.netty.util.HashedWheelTimer$HashedWheelTimeout.expire(HashedWheelTimer.java:672) ~[netty-common-4.1.58.Final.jar:4.1.58.Final]
at io.netty.util.HashedWheelTimer$HashedWheelBucket.expireTimeouts(HashedWheelTimer.java:747) ~[netty-common-4.1.58.Final.jar:4.1.58.Final]
at io.netty.util.HashedWheelTimer$Worker.run(HashedWheelTimer.java:472) ~[netty-common-4.1.58.Final.jar:4.1.58.Final]
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30) ~[netty-common-4.1.58.Final.jar:4.1.58.Final]
at java.base/java.lang.Thread.run(Thread.java:834) ~[na:na]
Once this happens, even if you stop the test, Redisson no longer recovers. All requests fail after 6 seconds and you have to restart the server for it to work again.
By the way, those 6 seconds seem to be related to retryAttempts and retryInterval settings, but even if I set retryAttempts to zero, it still takes 1.5 seconds for each request to fail. Why?
Anyways, the main problem is that it fails.
Steps to reproduce or test case I have created a clean spring boot project with one endpoint that executes a lua script. The script is basically rate limiting:
local count
local ttl
count = redis.call("incr",KEYS[1])
ttl = redis.call("ttl",KEYS[1])
if tonumber(ttl) == -1 then
redis.call("expire",KEYS[1],ARGV[1])
end
return count
The endpoint just takes the IP of the request (from a “True-client-ip” header) and executes the script with it, returning the IP and the number of requests made so far this minute so you can see if it is working or not.
And the test makes a bunch of requests to this endpoint, faking the True-client-ip header with 50 different IPs in an attempt to simulate a realistic environment.
So, how to test:
demo.zip
- Download and extract the demo project
- Change RedissonConfiguration to connect to a redis cluster. Ours has 3 master and 3 slaves.
- Start the server and see if
localhost:8080/redissonworks on your browser. - Start Locust with
locust -f demo.pyfrom the root project directory (you will need to install locust withpip3 install locust) - Open Locust UI on your browser (
localhost:8089) and enter the following parameters: 20 users, 5 spawn rate,http://localhost:8080 - Wait a couple minutes for the server to explode (hopefully)
Redis version Redis server v=4.0.6
Redisson version 3.14.1
Redisson configuration Nothing fancy:
clusterConfig.setMasterConnectionPoolSize(100);
clusterConfig.setSlaveConnectionPoolSize(64);
[and the redis cluster nodes]
And those numbers probably are not even important, but now that I have managed to reproduce the error I don’t want to change them. Check RedissonConfiguration for the details.
Issue Analytics
- State:

- Created 3 years ago
- Comments:9 (6 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Fixed
Good news!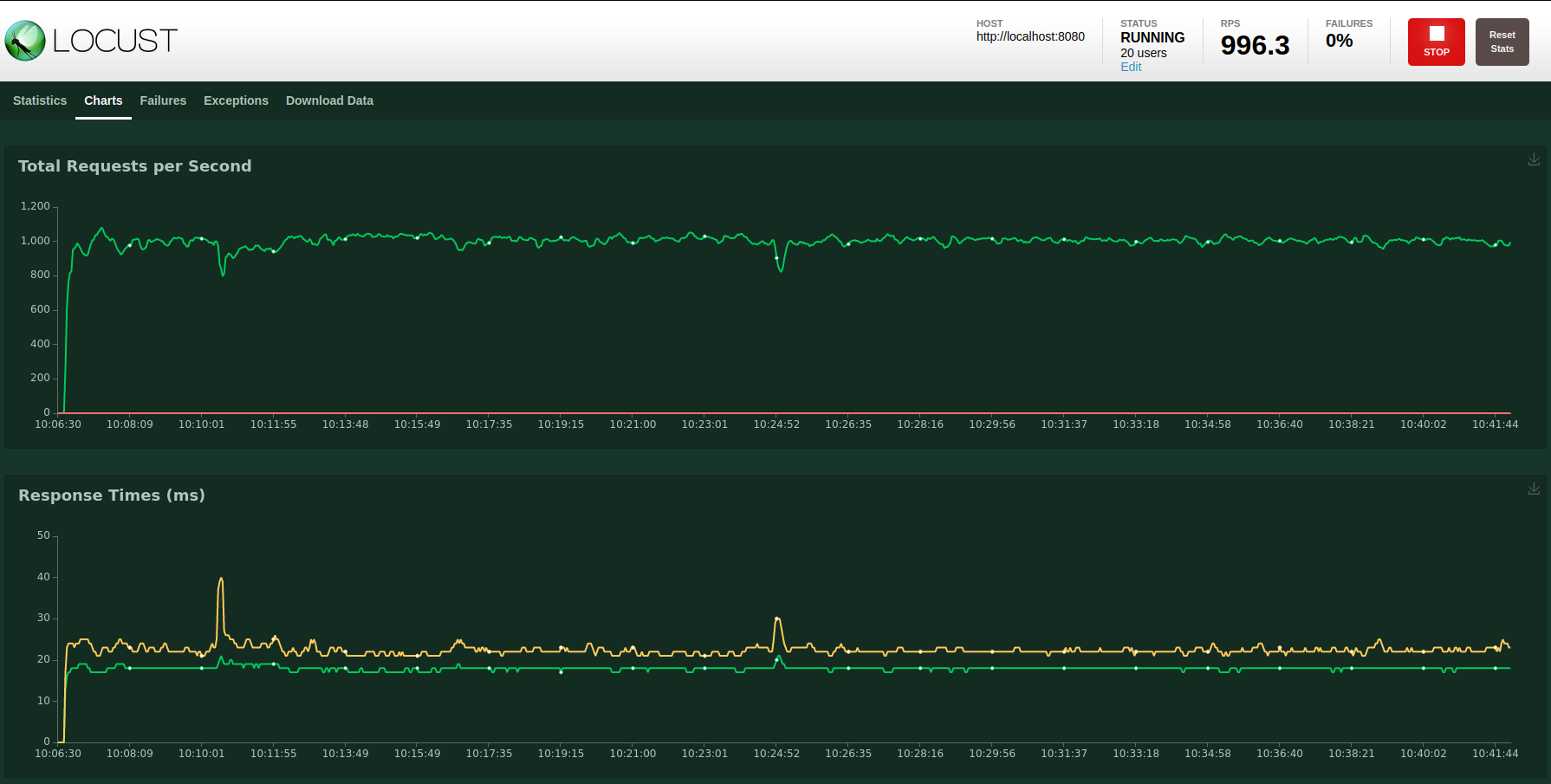 Using that jar the test has been running for 40 minutes so far without a single error.
I have had to add a few dependencies, on top of the jar, otherwise it wouldn’t start:
Using that jar the test has been running for 40 minutes so far without a single error.
I have had to add a few dependencies, on top of the jar, otherwise it wouldn’t start:
Oh and I no longer see RedisMovedExceptions on the JMC recording.
I have tried v3.14.1 again just to make sure the bug was still present and yep, in a couple minutes it failed.
Amazing @mrniko thank you so much! What was it?