
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Don't allow criterion='mae' for gradient boosting estimators
See original GitHub issueThe MAE criterion for trees was introduced in https://github.com/scikit-learn/scikit-learn/pull/6667. This PR also started exposing the criterion parameter to GradientBoostingClassifier and GradientBoostingRegressor, thus allowing ‘mae’, ‘mse’, and ‘friedman_mse’. Before that, the GBDTs were hardcoded to use ‘friedman_mse’.
I think we should stop allowing criterion='mae' for GBDTs.
My understanding of Gradient Boosting is that the trees should be predicting gradients using a least squares criterion. If we want to minimize the absolute error, we should be using loss='lad', but the criterion used for splitting the tree nodes should still be a least-squares (‘mse’ or ‘friedman_mse’). I think that splitting the gradients using mae isn’t methodologically correct.
In his original paper, Friedman does mention the possibility to fit a tree to the residuals using an lad criterion. But never does he suggest that one could fit the trees to the gradients using lad, which is what we are currently allowing.
I ran some benchmarks on the PMLB dataset (most datasets are balanced hence accuracy is a decent measure).
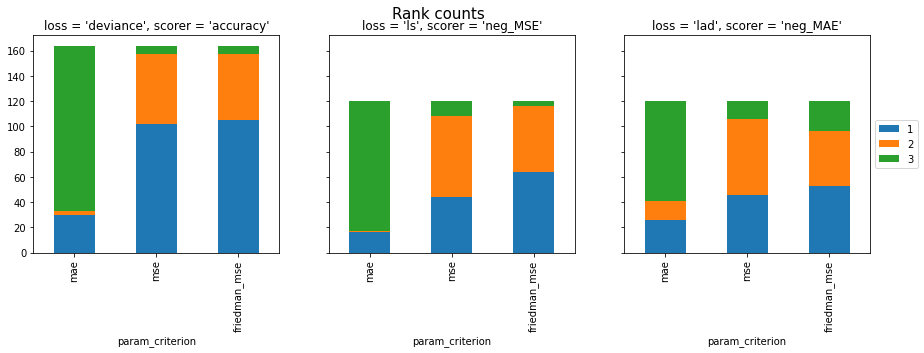
We can see that using criterion=mae usually perfoms worse than using mse or friedman_mse, even when loss=lad. Also, criterion=mae is 60 times slower than the other criteria (see notebook for details).
Note: From the benchmarks, friedman_mse does seem to (marginally) outperform mse, so I guess keeping it as the default makes sense. CC @thomasjpfan @lorentzenchr
Issue Analytics
- State:

- Created 3 years ago
- Reactions:3
- Comments:6 (5 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
@nikhilreddybilla28, this issue was already claimed by @madhuracj
take