
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Reconsider default of `max_features` of RandomForestRegressor
See original GitHub issueIn https://github.com/scikit-learn/scikit-learn/issues/7254, there was a long discussion on max_features defaults for random forests. As a consequence, the default “auto” was changed to “sqrt” for RandomForestClassifier, but unfortunately not for RandomForestRegressor. I would like to reconsider this decision.
What to change?
The default of RandomForestRegressor’s max_features = "auto" should point to m/3 or sqrt(m), where m is the number of features.
Why?
-
Good defaults are essential for random forests. The fact that random forests do well even without hyperparameter tuning is one of their only advantages over boosted trees.
-
Every implementation in R and also h2o use sqrt(m) or m/3 as default. R’s
rangerpackage uses sqrt(m) for both regression and classification. https://github.com/imbs-hl/ranger -
Column subsampling per split is the main source of randomness, leading to less correlated trees. The current default removes this effect. Strictly speaking, the current default does not fit a proper random forest but rather a bagged tree. My experience shows that random forests perform better than bagged trees in the majority of the cases.
-
Training time is proportional to
max_features. I.e. one could easily run 500 trees instead of 100 with a better default.
Note: I am not talking about defaults for completely randomized trees, just about proper random forests.
Issue Analytics
- State:

- Created 2 years ago
- Reactions:1
- Comments:34 (31 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Curious about the effects of
max_featuresin regression problems, I did an analysis (thanks @thomasjpfan for your sk_encoder_cv repo!), see https://github.com/lorentzenchr/notebooks/blob/master/random_forests_max_features.ipynb.5-fold CV: MSE and uncertainty (std)
Smaller is better.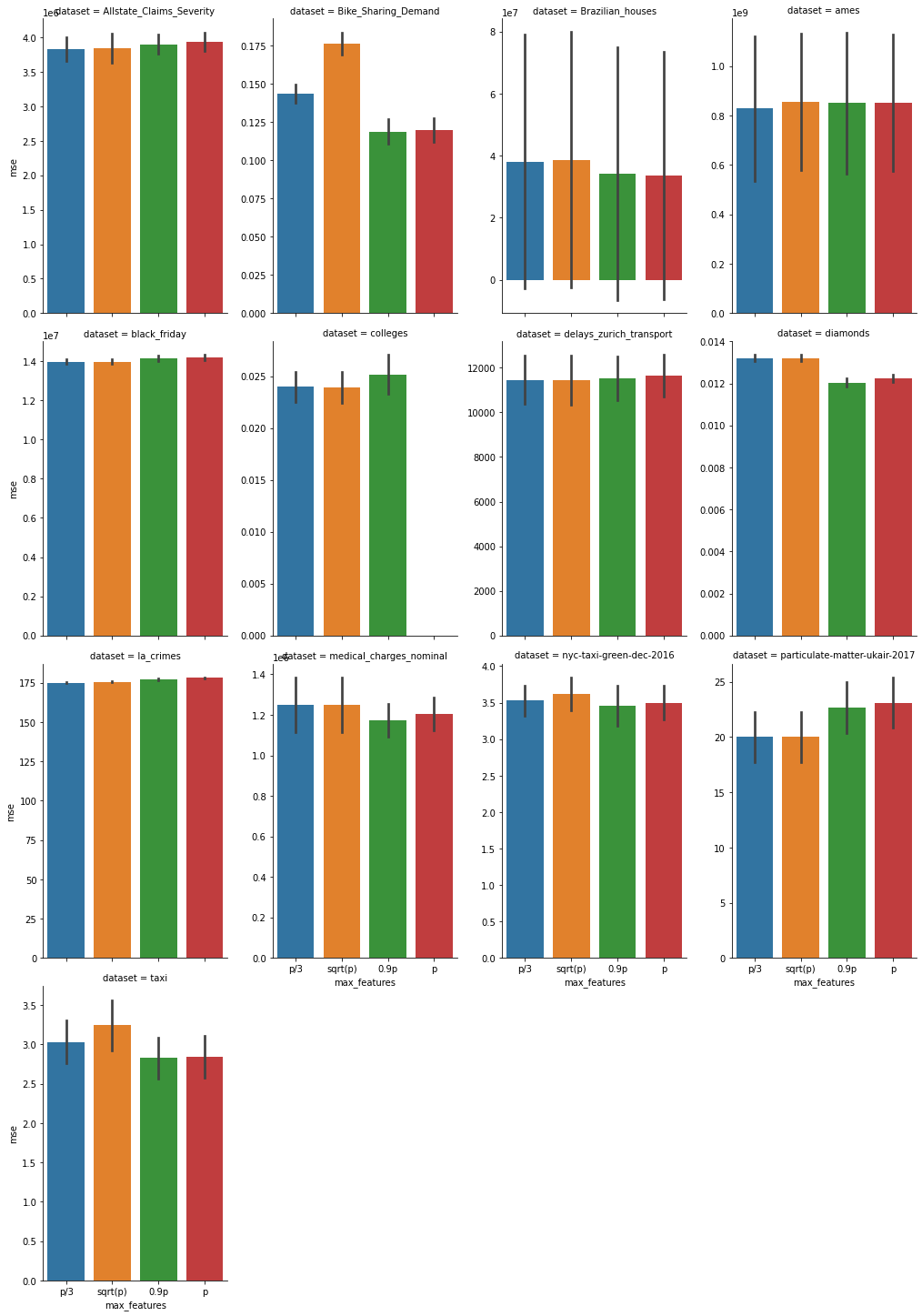
Fit times
Smaller is better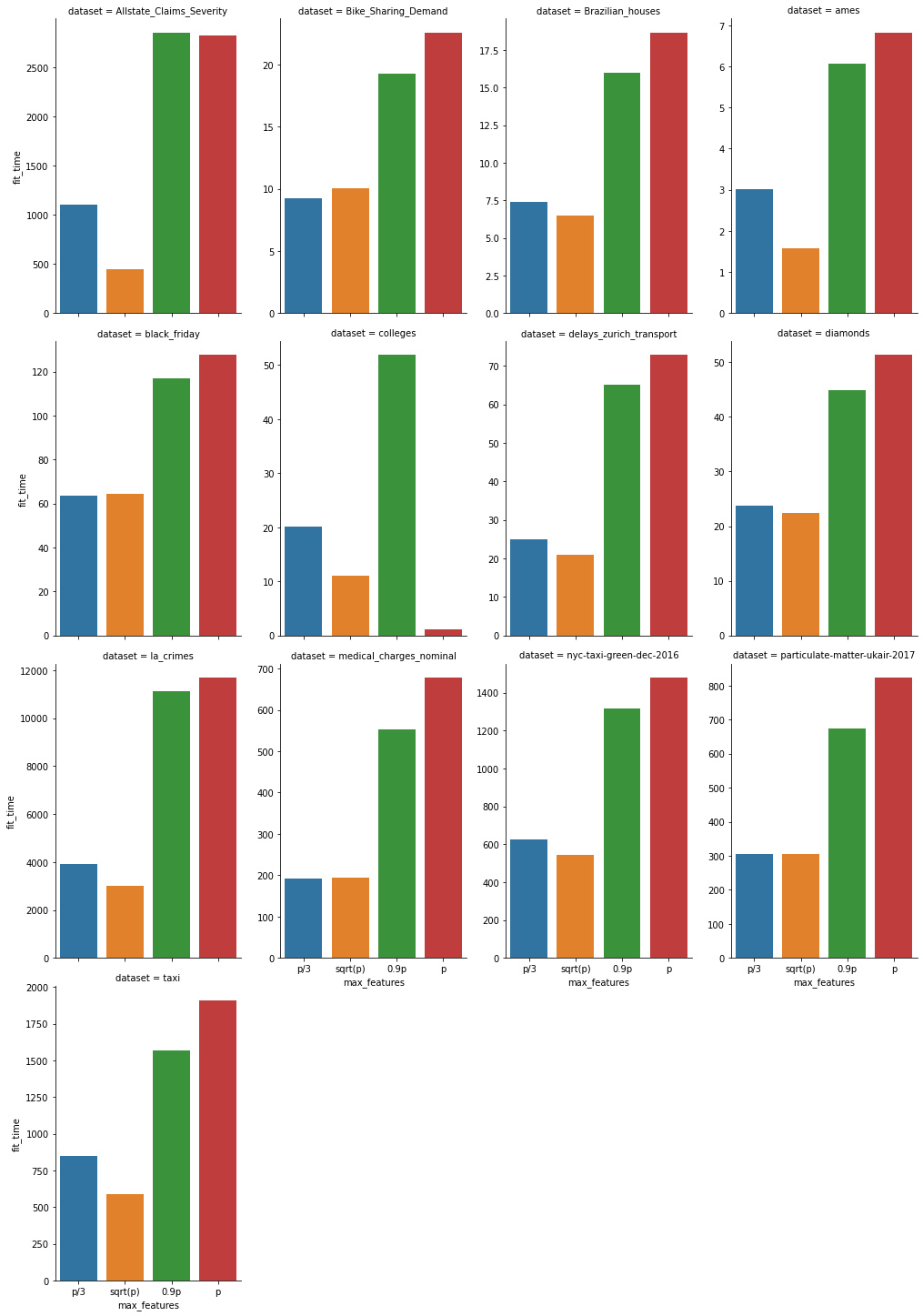
Full table in details.
we already allow floats so that’s equivalent to
max_features=.33andmax_features=.9: