
Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Attension Network explanation?
See original GitHub issueThanks for you tutorial! I found in READEME.md and code:
def forward(self, encoder_out, decoder_hidden):
"""
Forward propagation.
:param encoder_out: encoded images, a tensor of dimension (batch_size, num_pixels, encoder_dim)
:param decoder_hidden: previous decoder output, a tensor of dimension (batch_size, decoder_dim)
:return: attention weighted encoding, weights
"""
att1 = self.encoder_att(encoder_out) # (batch_size, num_pixels, attention_dim)
att2 = self.decoder_att(decoder_hidden) # (batch_size, attention_dim)
att = self.full_att(self.relu(att1 + att2.unsqueeze(1))).squeeze(2) # (batch_size, num_pixels)
alpha = self.softmax(att) # (batch_size, num_pixels)
attention_weighted_encoding = (encoder_out * alpha.unsqueeze(2)).sum(dim=1) # (batch_size, encoder_dim)
return attention_weighted_encoding, alpha
You implement the attension function $f_att(a_i, h_{t-1}$ as below:
added and ReLU activated. A third linear layer transforms this result to a dimension of 1
And I want to know is this your own method or you fellow a paper(could you give me a link)? And will a concat of att1 and att2 be better?
Issue Analytics
- State:

- Created 5 years ago
- Comments:11 (2 by maintainers)
 Top Results From Across the Web
Top Results From Across the Web
Intuitive Understanding of Attention Mechanism in Deep ...
This is a slightly advanced tutorial and requires basic understanding of sequence to sequence models using RNNs.
Read more >Attention (machine learning) - Wikipedia
In artificial neural networks, attention is a technique that is meant to mimic cognitive attention. The effect enhances some parts of the input...
Read more >Attention Mechanism In Deep Learning - Analytics Vidhya
In psychology, attention is the cognitive process of selectively concentrating on one or a few things while ignoring others. A neural network is ......
Read more >The Attention Mechanism from Scratch
The idea behind the attention mechanism was to permit the decoder to utilize the most relevant parts of the input sequence in a...
Read more >A Beginner's Guide to Attention Mechanisms and Memory ...
Attention mechanisms are components of memory networks, which focus their attention on external memory storage rather than a sequence of hidden states in...
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
@roachsinai This is the result of Show, Attend and Tell paper here. It is stated at the top of the tutorial. Moreover, you can visualize this diagram I drew for how the attention is calculated. Hope it helps!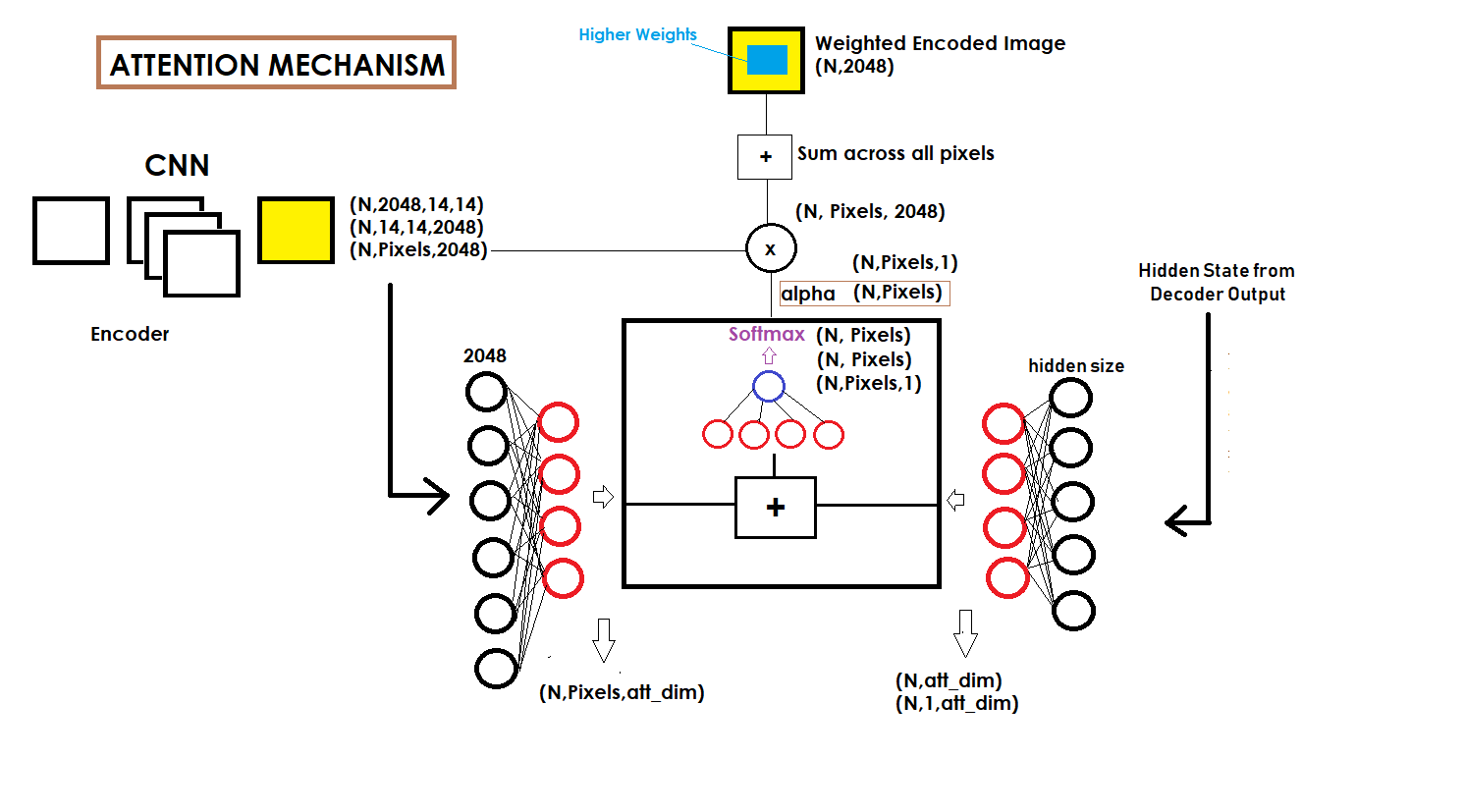
@sgrvinod thanks for the wonderful code and tutorial. I had a question on the attention part. As per my understanding, the flattened encoder output is (N,196,2048) and the attention weights (alpha) is (N,196). So, every pixel in a channel is multiplied by a weight and this weight remains the same for corresponding pixels in all the channels. My question is, can we have an alpha matrix-like (N, 2048) where every channel gets multiplied by a different weight and all the pixels in a particular channel share the same weight.
Can you please explain how one approach is better than the other?