
Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
st.write (df) gives problem when df is a pivot table
See original GitHub issueSummary
Showing a dataframe gives an error ArrowInvalid: (‘Could not convert All with type str: tried to convert to int’, ‘Conversion failed for column MM with type object’)
Steps to reproduce
Code snippet:
import pandas as pd
import streamlit as st
def get_data():
url = "https://raw.githubusercontent.com/rcsmit/streamlit_scripts/main/input/garminactivities_new.csv"
df = pd.read_csv(url, delimiter=';')
df["Datum"] = pd.to_datetime(df["Datum"], format="%d-%m-%Y")
df = df.sort_values(by=['Datum'])
df["YYYY"] = df["Datum"].dt.year
df["MM"] = df["Datum"].dt.month
df["DD"] = df["Datum"].dt.day
df["count"] = 1
df = df[df["Activiteittype"] == "Hardlopen"].copy(deep=False)
df = df[["Datum","Titel", "Afstand","Tijd", "gem_snelh", "count", "MM", "YYYY"]]
return df
def find_nr_activities_per_month_per_year(df):
# Aantal activiteiten per maand (per jaar)
df_pivot = df.pivot_table(index='MM', columns='YYYY', values='count', aggfunc='sum', fill_value=0, margins = True)
st.write(df_pivot) #gives error
print (df_pivot) # not a problem
def main():
df = get_data().copy(deep=False)
find_nr_activities_per_month_per_year(df)
if __name__ == "__main__":
main()
Dtypes of the dataframe:
Datum datetime64[ns]
Titel object
Afstand float64
Tijd object
gem_snelh float64
count int64
MM int64
YYYY int64
Expected behavior:
Showing the dataframe. print(df) doesn’t throw an error
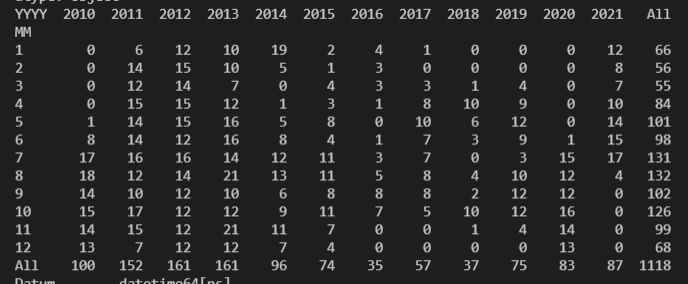
Actual behavior:


Is this a regression?
I don’t know
Debug info
- Streamlit version: 0.85
- Python version: 3.8
- Using Conda? PipEnv? PyEnv? Pex? Nothing of this
- OS version: Windows
- Browser version: Chrome, latest
Additional information
n/a
Issue Analytics
- State:

- Created 2 years ago
- Comments:6
 Top Results From Across the Web
Top Results From Across the Web
How can I pivot a dataframe? - Stack Overflow
Question 1 · Good general approach for doing just about any type of pivot · You specify all columns that will constitute the...
Read more >Apply automatic column type fixes for additional errors #5477
Context We already transform some dataframe column types (mixed columns) that are ... Closes st.write (df) gives problem when df is a pivot...
Read more >A Guide to Pandas Pivot Table - Built In
In the pivot_table function, we specify the DataFrame we are summarizing, and then the column names for the values, index and columns.
Read more >Reshaping and pivot tables — pandas 1.5.2 documentation
pivot () will error with a ValueError: Index contains duplicate entries, cannot reshape if the index/column pair is not unique. In this case,...
Read more >Pandas .groupby(), Lambda Function, & Pivot Table Tutorial
This lesson of the Python Tutorial for Data Analysis covers grouping data with pandas .groupby(), using lambda functions and pivot tables, and sorting...
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
Hi @rcsmit, sorry for the delayed reply – I missed your last reply until now. The error seems to be related / probably has the same root cause, so I don’t think there’s a need to open a second issue.
Thanks a lot for your reply and help.
For those who arrive here after googling
does the job (
.str.zfill(2)is to prevent the 1 10 11 12 3 4 etc order)