
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Very slow performance with TVP (500 rows insert via stored procedure TVP)
See original GitHub issueThis is a clone of an issue I posted in node-mssql: #1308. I’m reposting here as the issue appears to be with the tedious driver. Specifically with lib/tracking-buffer/writable-tracking-buffer.js
Possibly related to: #1093, #879 ?
I’m sending a request to a stored procedure which accepts a TVP parameter. My TVP has 5 columns and only 500 rows. One of the columns contains an NVARCHAR(MAX) which is a stringified JSON object literal. The stringified object averages 5,000 characters in length (max: 10,000)
It’s taking 15 seconds for request.execute() (in node-mssql) to complete with only 500 rows in the TVP. This is a big issue for me as I need to send 2M rows (in batches of 500) in an overnight batch job.
I’ve checked the SQL execution time using SQL Profiler tracing and it completes in < 0.5 seconds once the sproc actually executes. There is a long lag between calling request.execute() and SQL Profiler actually detecting the query request. So, 14.5 seconds (96.7%) of execution is before it is sent to SQL server.
The slowness has been verified to not be due to: (a) data transfer overhead: both the app and SQL are running on localhost and data transfer is extremely fast. (b) the box itself: many other code operations complete at expected speeds.
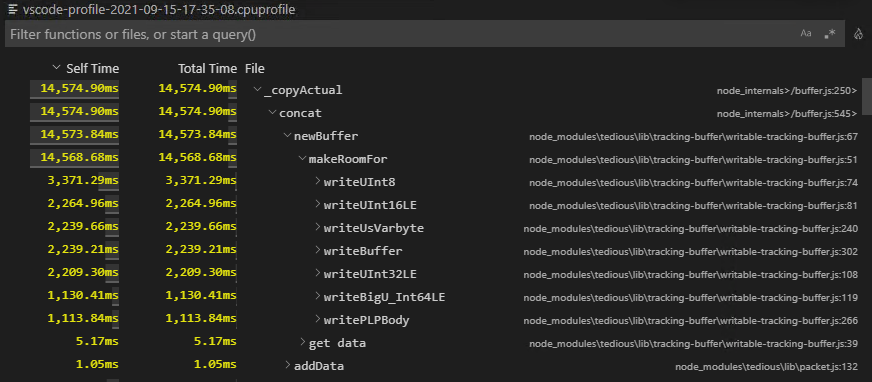
Using a CPU Profile snapshot in VSCode, I have isolated this bottleneck to lib/tracking-buffer/writable-tracking-buffer.js
Expected behaviour:
I would expect execution time to be at least faster than inserting the 500 rows as 500 single executions on a stored procedure which does not accept a TVP and instead accepts each row of 5 columns as 5 separate input parameters (with the same SQL datatypes as the columns of the TVP). I have tested this scenario and the write time end-to-end is 6 seconds on the same machine (including the data transfer and SQL sproc execution time) - significantly faster. I thought the whole point of a TVP input was to improve the performance of repetitive sproc executions, by performing them in bulk.
Actual behaviour:
14 seconds execution time. Here is a CPU profile of the offending part of the stack trace:
Configuration:
Here is the node-mssql configuration using TVP
14 seconds for 500 rows:
// create the tvp object - this is FAST
const tvp = new sql.Table()
tvp.columns.add('FileId', sql.UniqueIdentifier)
tvp.columns.add('FileNumber', sql.BigInt)
tvp.columns.add('FileVersion', sql.VarChar(20))
tvp.columns.add('FileCommitID', sql.VarChar(40))
tvp.columns.add('FileModel', sql.NVarChar(sql.MAX))
// add the rows to the TVP - this is FAST
tvp.rows = arr.map(function(r) {
delete r.text
// Columns should be in the same order as the columns added above
return [
r.uuid, // FileId
r.FileNumber, // FileNumber
version.version, // FileVersion
version.hash, // FileCommitID
JSON.stringify(r), // FileModel
]
})
// Assign the TVP as a sproc parameter - FAST
request.input('ResultRecords', sql.TVP('[Files].[type_Result]'), tvp)
// Execute the request - this is SLOW - 14.5 seconds for 500 records
try {
return await request.execute('[Files].[usp_insertResults]') // sproc handles a table of records
} catch (e) {
console.log(`SQL ERROR: ${e.toString()}`)
return { rows: 0 }
}
Here is a similar insert, which sends one row at a time to a sproc that receives the table columns as individual input parameters 6 seconds for 500 rows
const request = new sql.Request(pool)
request.input('FileId', sql.UniqueIdentifier, obj.uuid)
request.input('FileNumber', sql.BigInt, obj.FileNumber)
request.input('FileVersion', sql.NVarChar(20), version.version)
request.input('FileCommitID', sql.VarChar(40), version.hash)
request.input('FileModel', sql.NVarChar(sql.MAX), JSON.stringify(obj || {}))
try {
return await request.execute('[Files].[usp_insertResult]') // sproc handles a single record
} catch (e) {
console.log(`SQL ERROR: ${e.toString()}`)
return null
}
Software versions
- NodeJS: 14.17.4
- node-mssql: 7.2.1
- SQL Server: Microsoft SQL Server 2017 (RTM-CU25) (KB5003830) - 14.0.3401.7 (X64)
- Operating System: Windows Server 2019
Issue Analytics
- State:

- Created 2 years ago
- Comments:11
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
@thegoatherder Thank you for the detailed response! 🙏
mssqlis a wrapper that abstracts overtediousand optionally allows using the nativemsnodesqlv8driver instead oftedious. There’s a few features thattediousdoes not support (like integrated Active Directory authentication) butmsnodesqlv8does, so for some users it can make sense to have the ability to swap out the low level driver without having to rewrite the whole application.I don’t think anything is wrong with using
mssqlinstead oftedious, it’s a great piece of software and a lot of users are very happily using it. But I also like to understand what the reasons are for users for using one over the other. It also can help point me prioritize working on specific (existing or new) features.mssqllives under thetediousjsorganization, but it’s two different teams working on the two libraries. We try to ensure that we don’t breakmssqlif we do changes ontedious, and themssqlteam provides great feedback back to us on what we improve, but in the end development happens separately.In a perfect world, we’d slowly absorb more and more features from
mssqlintotedious, and at some point in the future, there would be no need to have a separate library on top oftedious. But we’re definitely not there yet, and movement into that direction often is slow due to low number of contributors.This is something that is absent from
tedious. I’d love to support this one day with a rich and feature complete pooling implementation, but it’s not high on my priority list right now.This is also missing from
tedious. It requires changing some of the existing APIs, so it’s not an easy change to make. I’ve been thinking about this more recently, because it’s a huge improvement to the ease of use oftedious, but I’d like to spend some more time mulling over this and get the implementation/API right the first time.This is pretty much the same as the
async/await.I’m wondering how this is implemented in
mssql, becausetediousdoes not support streaming in many areas andmssqlis built on top of it. Would be interesting to better understand how this is implemented and if we can do something on thetediousside similar to it.This is supported by
tediousdirectly.This is supported by
tediousdirectly, although the API is awkward to use and I’d like to improve this.This is supported by
tediousdirectly.This is supported by
tediousdirectly.Anyway, thanks for the great feedback! ❤️ If you run into any other issues with
tediousormssql, feel free to reach out to us again.I’m glad to hear the issue has been resolved!
Just as a heads up, I recently noticed that we’re not handling
varcharencoding correctly in TVPs. If yourvarcharvalues only contain ASCII values, you won’t notice this issue, but if they contain any non-ASCII character data might get mangled and be incorrect. I’ll open a PR that will fix this in the next few days.Out of curiosity, is there anything specific why you’re using
mssqlovertediousdirectly? I’m just trying to understand the use-cases that lead people to use one over the other, and what we can improve on thetediousside to bring people to usetediousdirectly instead. 😅