
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Quantization: QuantizeModelsTest.testModelEndToEnd() function does not check the correctness of quantization process
See original GitHub issueDescribe the bug
Hi, I’m trying to understand the model optimization API and create quantized version of
the MobileNetV2 model for my side project (a small library for training custom detection models for mobile). However, I’m struggling to get any positive results using this library compared to old approach when I was using converter.representative_dataset for model conversion.
I found that there are some end-to-end tests in your repository in the
tensorflow_model_optimization.python.core.quantization.keras.quantize_models_test.py file,
however it seems these tests do not check whether the conversion actually makes sense or not. I mean the conversion is successful but it is so inaccurate that cannot be used in practice.
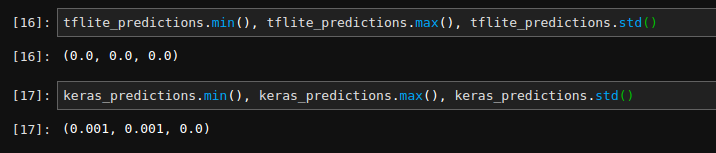
If you will check the predictions outputs of converted model you will see it produces only zeros (I get similar behavior when training on real data for much longer time).
The picture below shows the min/max and std values of the output of the converted MobileNetV2 model from your end to end test:
When I initialize this model with imagenet weights I still get different values at the outputs between keras quantized and converted to tflite model:
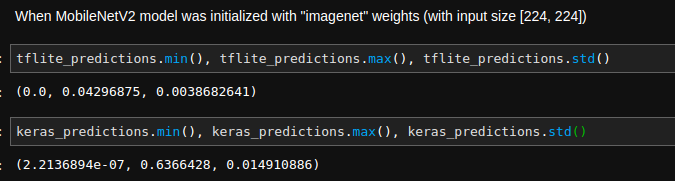
What are your general suggestions for checking for possible sources of invalid conversion? For example, I’m aware that I should finetune my quantized model for a couple of epochs, however I’m not sure how long or if this actually matters. Are batchnorm layers supported (I saw that composition of ConvBatchNormRelu is implemented). In general (or maybe in near future), should I expect to get similar accuracy of quantized Keras model and converted to tflite one ?
Thanks, Krzysztof
System information
TensorFlow installed from (source or binary): binary
TensorFlow version: tf-nightly==2.2.0.dev20200316
TensorFlow Model Optimization version: tf-model-optimization-nightly==0.2.1.dev20200320 (compiled from source code, from master branch)
Python version: 3.7.0
Code to reproduce the issue
This is slightly modified version of the _verify_tflite function from your tests, which I used to check the outputs of the converted models.
def _verify_tflite(tflite_file, x_test, y_test, model):
interpreter = tf.lite.Interpreter(model_path=tflite_file)
interpreter.allocate_tensors()
input_index = interpreter.get_input_details()[0]['index']
output_index = interpreter.get_output_details()[0]['index']
keras_predictions = model.predict(x_test)
tflite_predictions = []
for x, _ in zip(x_test, y_test):
x = x.reshape((1,) + x.shape)
interpreter.set_tensor(input_index, x)
interpreter.invoke()
outputs = interpreter.get_tensor(output_index)
tflite_predictions.append(outputs)
return np.vstack(tflite_predictions), keras_predictions
tflite_predictions, keras_predictions = _verify_tflite(tflite_file, x_train, y_train, base_model)
print(tflite_predictions.min(), tflite_predictions.max(), tflite_predictions.std())
print(keras_predictions.min(), keras_predictions.max(), keras_predictions.std())
Issue Analytics
- State:

- Created 4 years ago
- Comments:19 (8 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
This is a duplicate of this bug. Closing this, and following up there.
Thanks for noticing it @kmkolasinski. Just fixed it.