
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
I get random mel outputs when I training Tacotron-2 from scratch with LJSpeech dataset
See original GitHub issueI use the most recent code and the standard LJSpeech dataset. When i inference the model, the model generates random mel outputs after the correct voice in most times.
I use the code for inference from Huggingface Hub:
import soundfile as sf
import numpy as np
import tensorflow as tf
from tensorflow_tts.inference import AutoProcessor
from tensorflow_tts.inference import AutoConfig
from tensorflow_tts.inference import TFAutoModel
pretrained_mapper = "./tensorflow_tts/processor/pretrained/ljspeech_mapper.json"
pretrained_model_config = "./examples/tacotron2/conf/tacotron2.v1.yaml"
pretrained_model = "./examples/tacotron2/exp/train.tacotron2.v1/checkpoints/model-70000.h5"
pretrained_generator_config = "./examples/multiband_melgan/conf/multiband_melgan.v1.yaml"
pretrained_generator = "./examples/multiband_melgan/pretrained/tts-mb_melgan-ljspeech-en.h5"
pretrained_model_sampling_rate = 22050
processor = AutoProcessor.from_pretrained(pretrained_mapper)
model_config = AutoConfig.from_pretrained(pretrained_model_config)
tacotron2 = TFAutoModel.from_pretrained(pretrained_model, model_config)
generator_config = AutoConfig.from_pretrained(pretrained_generator_config)
mb_melgan = TFAutoModel.from_pretrained(pretrained_generator, generator_config)
input_text = "This is a demo to show how to use our model to generate mel spectrogram from raw text."
print("input_text>>>>", input_text)
input_ids = processor.text_to_sequence(input_text)
print("phoneme seq: {}".format(input_ids))
# tacotron2 inference (text-to-mel)
decoder_output, mel_outputs, stop_token_prediction, alignment_history = tacotron2.inference(
input_ids=tf.expand_dims(tf.convert_to_tensor(input_ids, dtype=tf.int32), 0),
input_lengths=tf.convert_to_tensor([len(input_ids)], tf.int32),
speaker_ids=tf.convert_to_tensor([0], dtype=tf.int32),
)
print(type(mel_outputs))
print(mel_outputs.shape)
# melgan inference (mel-to-wav)
audio = mb_melgan.inference(mel_outputs)[0, :, 0]
# save to file
sf.write('./audio.wav', audio, pretrained_model_sampling_rate, "PCM_16")
After the inference, the code will print mel_outputs.shape like this:
(1, 470, 80)
If the middle number is in range of 400-600, it will be a good result with no random data. I tested the models trained with 10k - 70k iters, and collected all the middle numbers listed below. It shows that the models are not so reliable.
Is my inference code wrong or what happened to the models training.
<html xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:x="urn:schemas-microsoft-com:office:excel" xmlns="http://www.w3.org/TR/REC-html40"> <head> <meta name=ProgId content=Excel.Sheet> <meta name=Generator content="Microsoft Excel 12"> <link id=Main-File rel=Main-File href="file:///C:\Users\Faye\AppData\Local\Temp\msohtmlclip1\01\clip.htm"> <link rel=File-List href="file:///C:\Users\Faye\AppData\Local\Temp\msohtmlclip1\01\clip_filelist.xml"> <style> </style> </head> <body link=blue vlink=purple>| Round 1 | Round 2 | Round 3 | Result – | – | – | – | – 10k | 2372 | 3966 | 4000 | Random 20k | 502 | 578 | 489 | Pass 30k | 4000 | 533 | 3518 | Random 40k | 552 | 511 | 547 | Pass 50k | 4000 | 4000 | 4000 | Random 60k | 498 | 525 | 4000 | Random 61k | 494 | 515 | 528 | Pass 62k | 518 | 4000 | 484 | Random 63k | 4000 | 4000 | 468 | Random 64k | 497 | 4000 | 4000 | Random 65k | 4000 | 4000 | 4000 | Random 66k | 509 | 484 | 4000 | Random 67k | 4000 | 491 | 3566 | Random 68k | 484 | 481 | 476 | Pass 69k | 4000 | 4000 | 505 | Random 70k | 470 | 476 | 492 | Pass
</body> </html>Issue Analytics
- State:

- Created 2 years ago
- Comments:9
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Update: I modified the batch_size from 32 to 16. I tested the models of 10k, 15k, 20k, 25k, 30k. It looks that the quality of the model is more predictable. I think i can close this issue.
@dathudeptrai I tested window 3 and 1, looks no improvements: https://drive.google.com/drive/folders/14ckSy9a4xBu29opPaQ-OsuWx4DqyvfKK?usp=sharing
Does it related to the training process. I use nvidia’s docker 21.03-tf2-py3 with one 3090 GPU. And later updated to 21.06-tf2-py3. The TensorBoard of training looks fine. But i got this random issue in inference.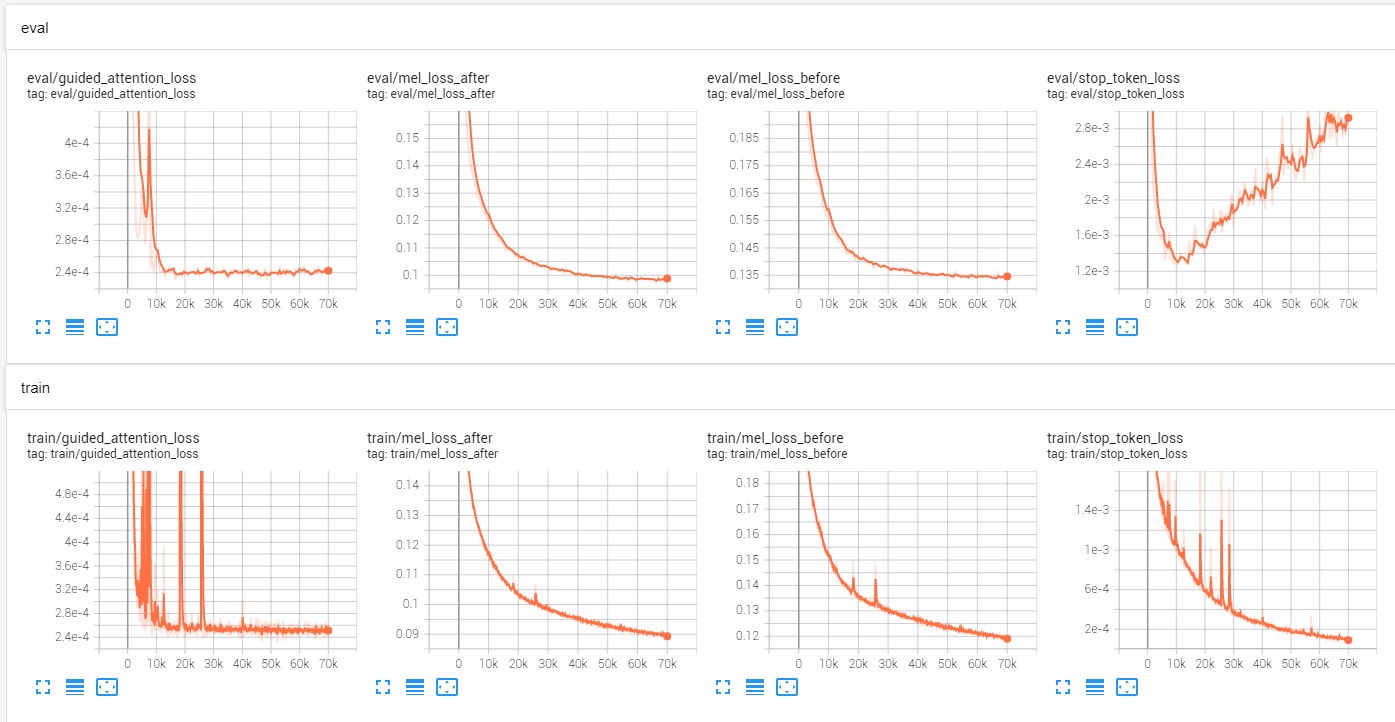
I trained Tacotron2 with Baker dataset (Chinese language) in couple weeks ago. It’s all fine in training and inference.