
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
[tacotron2 baker] Extra repetitive syllables synthesized at the end of the audio.
See original GitHub issueSubject of the issue
Retrained tacotron2 with baker dataset, mel spectrogram generated has extra repetitive syllables at the end. Please see the figure and check the audio.

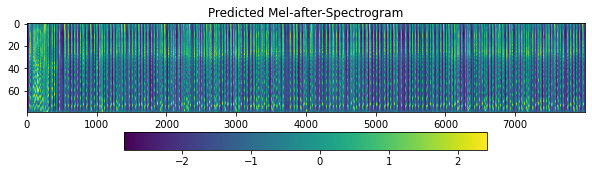 synth_wav.zip
synth_wav.zip
environment
TF 2.3.1 tensorflowTTS pulled at 2020/12/31
Steps to reproduce
- preprocess baker dataset, the ids contains the “eos” symbol 218 at the end. e.g.
[ 1, 6, 208, 2, 13, 41, 2, 25, 216, 4, 16, 106, 2,
6, 179, 4, 10, 194, 2, 20, 200, 3, 6, 51, 2, 6,
216, 3, 14, 118, 2, 19, 34, 2, 10, 57, 3, 21, 64,
2, 25, 205, 1, 218]
- Use this config for tacotron2 training. I use 128 batch_size to fill the GPU memory, so that I reduce the
train_max_steps: 50000to 50k, I expect training less steps because of using a large batch_size
###########################################################
# FEATURE EXTRACTION SETTING #
###########################################################
hop_size: 300 # Hop size.
format: "npy"
###########################################################
# NETWORK ARCHITECTURE SETTING #
###########################################################
model_type: "tacotron2"
tacotron2_params:
dataset: baker
embedding_hidden_size: 512
initializer_range: 0.5
embedding_dropout_prob: 0.1
n_speakers: 1
n_conv_encoder: 5
encoder_conv_filters: 512
encoder_conv_kernel_sizes: 5
encoder_conv_activation: 'relu'
encoder_conv_dropout_rate: 0.5
encoder_lstm_units: 256
n_prenet_layers: 2
prenet_units: 256
prenet_activation: 'relu'
prenet_dropout_rate: 0.5
n_lstm_decoder: 1
reduction_factor: 2
decoder_lstm_units: 1024
attention_dim: 128
attention_filters: 32
attention_kernel: 31
n_mels: 80
n_conv_postnet: 5
postnet_conv_filters: 512
postnet_conv_kernel_sizes: 5
postnet_dropout_rate: 0.1
attention_type: "lsa"
###########################################################
# DATA LOADER SETTING #
###########################################################
batch_size: 128 # Batch size for each GPU with assuming that gradient_accumulation_steps == 1.
remove_short_samples: true # Whether to remove samples the length of which are less than batch_max_steps.
allow_cache: true # Whether to allow cache in dataset. If true, it requires cpu memory.
mel_length_threshold: 32 # remove all targets has mel_length <= 32
is_shuffle: true # shuffle dataset after each epoch.
use_fixed_shapes: true # use_fixed_shapes for training (2x speed-up)
# refer (https://github.com/tensorspeech/TensorflowTTS/issues/34#issuecomment-642309118)
###########################################################
# OPTIMIZER & SCHEDULER SETTING #
###########################################################
optimizer_params:
initial_learning_rate: 0.001
end_learning_rate: 0.00001
decay_steps: 37000 # < train_max_steps is recommend.
warmup_proportion: 0.02
weight_decay: 0.001
gradient_accumulation_steps: 1
var_train_expr: null # trainable variable expr (eg. 'embeddings|decoder_cell' )
# must separate by |. if var_train_expr is null then we
# training all variable
###########################################################
# INTERVAL SETTING #
###########################################################
train_max_steps: 50000 # Number of training steps.
save_interval_steps: 5000 # Interval steps to save checkpoint.
eval_interval_steps: 500 # Interval steps to evaluate the network.
log_interval_steps: 100 # Interval steps to record the training log.
start_schedule_teacher_forcing: 200001 # don't need to apply schedule teacher forcing.
start_ratio_value: 0.5 # start ratio of scheduled teacher forcing.
schedule_decay_steps: 50000 # decay step scheduled teacher forcing.
end_ratio_value: 0.0 # end ratio of scheduled teacher forcing.
###########################################################
# OTHER SETTING #
###########################################################
num_save_intermediate_results: 1 # Number of results to be saved as intermediate results.
- During the inference, the “eos” symbol number 218 is alos added to the end of the inference sentece. e.g.
[1, 27, 56, 2, 23, 116, 2, 6, 79, 2, 12, 56, 2, 15, 33, 2, 6, 204, 2, 10, 57, 2, 10, 168, 2, 10, 51, 2, 10, 168, 2, 27, 143, 2, 6, 184, 2, 6, 200, 2, 6, 118, 2, 13, 54, 2, 9, 69, 2, 25, 81, 2, 24, 145, 1, 218]
- The last step 50k loss:
2021-01-02 10:43:55,182 (base_trainer:978) INFO: (Step: 50000) train_stop_token_loss = 0.0000.
2021-01-02 10:43:55,183 (base_trainer:978) INFO: (Step: 50000) train_mel_loss_before = 0.0714.
2021-01-02 10:43:55,184 (base_trainer:978) INFO: (Step: 50000) train_mel_loss_after = 0.0625.
2021-01-02 10:43:55,184 (base_trainer:978) INFO: (Step: 50000) train_guided_attention_loss = 0.0004.
2021-01-02 10:43:55,190 (base_trainer:883) INFO: (Steps: 50000) Start evaluation.
2021-01-02 10:45:43,399 (base_trainer:897) INFO: (Steps: 50000) Finished evaluation (3 steps per epoch).
2021-01-02 10:45:43,400 (base_trainer:904) INFO: (Steps: 50000) eval_stop_token_loss = 0.0239.
2021-01-02 10:45:43,401 (base_trainer:904) INFO: (Steps: 50000) eval_mel_loss_before = 0.1437.
2021-01-02 10:45:43,402 (base_trainer:904) INFO: (Steps: 50000) eval_mel_loss_after = 0.1248.
2021-01-02 10:45:43,403 (base_trainer:904) INFO: (Steps: 50000) eval_guided_attention_loss = 0.0004.
Expected behaviour
I expect the model does the alignment correctly like this:
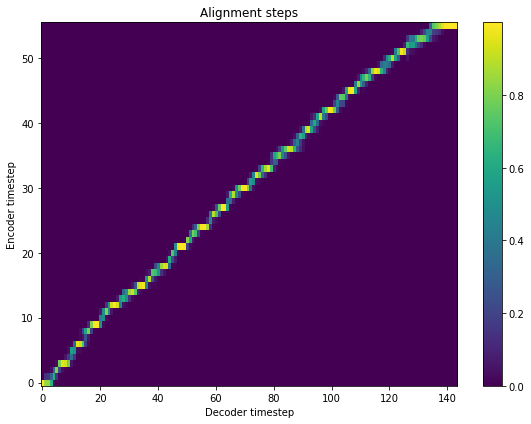
This figure is taken from the baker colab https://colab.research.google.com/drive/1YpSHRBRPBI7cnTkQn1UcVTWEQVbsUm1S?usp=sharing
The model is named “tacotron2-100k.h5”, so I assume it is trained 100k steps. The default batch_size is however smaller = 32
Issue Analytics
- State:

- Created 3 years ago
- Comments:14
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
@azraelkuan @wangwindlong @dathudeptrai This issue is solved by simply training with batch_size=32 😄 batch_size=128 might be the reason of this issue. I suspect that some short samples are mixed in a mini-batch, and large number of padding zeros confused the model. Any suggest to use large batch size? bucket_by_sequence_length?
@ronggong you can also check out the old branch and re-train, maybe there is a mismatch between each version 😃)). It’s really hard for me to make sure everything still works when I update new features + fix bugs since I focus on my private library and my dataset rather than the public dataset 😃.