
Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Batches of fibers may be scheduled unfairly in compute-heavy applications
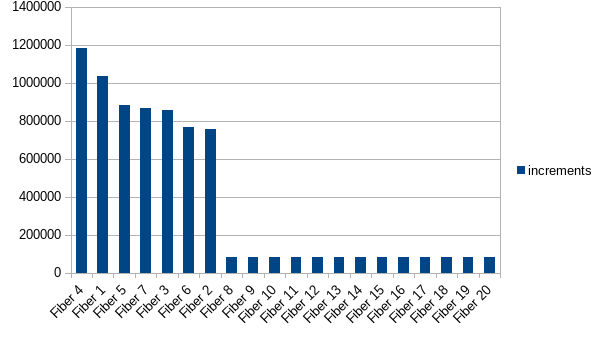
See original GitHub issueThis is the result of the following experiment:
- start
nfibers - each fiber has an
id - the fiber loops, infinitely incrementing an ID-bound value in a
Ref[IO, Map[String, Int]], where theStringis the fiber’sid, then yields withIO.cede.
The result is that the fibers that get started first get to do most of the incrementing (n = 20):
import cats.effect.{IO, IOApp, Ref}
import cats.implicits._
import scala.concurrent.duration._
object FairnessExperiment extends IOApp.Simple {
override def run: IO[Unit] = for {
ref <- Ref[IO].of(Map.empty[String, Int])
_ <- (1 to 20).map(i => loop(s"Fiber $i", ref)(0).start).toList.parSequence
_ <- (IO.sleep(1.second) >> ref.get >>= printCountsAsCsv).foreverM
} yield ()
def loop(id: String, ref: Ref[IO, Map[String, Int]])(i: Int): IO[Unit] = for {
_ <- ref.getAndUpdate(s => s.updatedWith(id)(v => Some(v.getOrElse(0) + 1)))
_ <- IO.cede
result <- loop(id, ref)(i + 1)
} yield result
private def printCountsAsCsv(counts: Map[String, Int]) = IO.delay {
val columns = counts.toList.sortBy(-_._2)
println(columns.map(_._1).mkString(","))
println(columns.map(_._2).mkString(","))
}
}
Issue Analytics
- State:

- Created 2 years ago
- Comments:23 (13 by maintainers)
 Top Results From Across the Web
Top Results From Across the Web
No results found
 Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
So the reason that
sleepandblockingchange the semantics here is they effectively remove the work-stealing pool’s ability to optimize itself! More precisely, in both situations you’re bouncing the fiber through a different execution context, which means that the returning continuations will come back through the external queue. The external queue is a single task source which all worker threads pull from, which should sound familiar: it’s the exact same thing thatFixedThreadPooldoes! In other words, by usingsleepandblockingrather thancede, you’re removing work stealing altogether, and you’re basically forcing the runtime to behave as if you had done anevalOnwith a fixed pool. This has some significant performance costs, as you noted.(note: we’re working on an optimization to
sleepwhich allows it to remain within the work-stealing pool and has several advantages, including removing this particular performance hit)Coming back to your broader question about workloads… I would say that, in general, you shouldn’t have to think too hard about it. Outside of very artificial scenarios (such as the test in this thread), the pool very rapidly converges to a near-optimal task distribution, even for heavily compute-bound tasks. The worst possible scenario is where you just start n fully-synchronous (no
async) fibers, where n >Runtime.getRuntime().availableProcessors(), and then you leave them running for an enormously long time and never start anything else. So in other words, what you see here. 😃 Even compute-bound scenarios tend to be different than this, with internal forking (e.g. the fibers themselves callingstartorpar-something),asyncusage, etc. Any of those things end up triggering the pool to progressively rebalance itself, which in turn results in better fairness.Even in the worst possible scenario though, what happens is all threads are active, but some fibers receive a lesser time share than other fibers. This is still okay in a sense, because the net average throughput is identical! This is a bit unintuitive, but it’s important to remember that fairness and throughput are not usually connected aside from the fact that improving one often means degrading the other. In this case, the throughput is at its theoretical maxima (outside of some subtle cache eviction behaviors) regardless of whether one worker handles 99% of the fibers while every other work handles just one, or if all workers handle the same number of fibers. No compute time is being wasted, and so the total average throughput across all fibers is identical to if there were an even distribution across all workers.
In the test, this “average throughput” manifests as the sum total number of counts across all fibers. The point I’m making is the sum across all fibers is the same in the current (unbalanced distribution) situation as it would be if we could somehow wave a magic wand and make all workers have the same number of fibers.
Fairness is more closely related to responsiveness and jitter. Intuitively, you can think of it in microservice terms: a new network request comes in (which manifests as an
asynccompletion), and some worker thread needs to pick that up and respond to it. How long does it take for that fiber continuation to get time on a worker? That is fairness. But, remember, we have definitionally ruled out that scenario in our test setup, because we said “noasync” and also “fork a set number of fibers and then never fork ever again”. So in other words, the test in the OP does do a decent job of artificially measuring fairness, but in doing so it constructs a scenario in which fairness is irrelevant, because it’s entirely throughput-bound and throughput is maximized!If you construct a scenario in which fairness matters (which will require the use of
async), you will also by definition trip the mechanisms in the pool which rebalance the workers, which in turn will ensure that fairness is preserved.All of which is to say that the work-stealing pool is a very safe default, even for these kinds of long-running CPU-bound scenarios, simply because the fairness tradeoffs it makes are definitionally irrelevant in such scenarios. Now, I’m not going to make the claim that this is the case for all possible scenarios, because I have no proof that this is the case, but this is why you can always use
evalOnand shift things over to aFixedThreadPool(or other) if you measure that it improves things.My 2 cents on this question. I would say, don’t treat fibers like threads. Threads are expensive to start, expensive to join, are well behaved when they are few and pinned to a CPU core each. Fibers on the other hand, are cheap to start, cheap to join and the more you have of them, the better the performance and scheduling fairness that you get (i.e. are well behaved when you create lots of them).
If your application cannot really be written in this manner, and you can measure that you’re actually running into a situation like this, you can use a
java.util.concurrent.FixedThreadPoolExecutorand it will most likely perform as well or better (in terms of performance or fairness, or both). Otherwise, just don’t worry about it. Work stealing is a fine default.Finally, we are computer scientists and engineers, and we know that there are no silver bullets in our profession, just tradeoffs.