
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Reproducibility issues to obtain a similar performance to the reported in the paper
See original GitHub issueDear authors,
First of all, congrats on the work you’ve done. I’m super excited to be able to reproduce your amazing results so that I can make my densepose implementation fast and light too! Unfortunately, I’ve been trying to reproduce your work in the past few days with no success.
Here the datails of what I did:
- Created a Docker container image from
nvidia/cuda:10.1-cudnn7-develthat:- Clones your repo to get the train_net tool.
- Installs dependencies:
- timm==0.1.16
- geffnet==1.0.2
- pycocotools==2.0.3
- scipy==1.5.4
- torch==1.6 (for cu101)
- torchvision==0.7 (for cu101)
- Installs detectron2 from source @ b1fe5127e41b506cd3769180ad774dec0bfd56b0
- Downloaded v2014 dataset, images and annotations from https://cocodataset.org/
- Trained from scratch 4 times with different BS and LR, with a train_net tool command like this:
python train_net.py --config-file ./configs/s0_bv2_bifpn_f64_s4x.yaml --num-gpus 2 SOLVER.IMS_PER_BATCH $BS SOLVER.BASE_LR $LR
Infra I used:
- Ubuntu machine with:
- 24 x Intel® Core™ i9-9920X CPU @ 3.50GHz, 2475 MHz
- 2 Titan RTX 24220MiB GPUs
Training Configuration:
_BASE_: "s0_bv2_bifpn.yaml"
MODEL:
FPN:
OUT_CHANNELS: 64
ROI_BOX_HEAD:
CONV_DIM: 64
ROI_SHARED_BLOCK:
ASPP_DIM: 64
CONV_HEAD_DIM: 64
SOLVER:
MAX_ITER: 490000
STEPS: (415000, 465000)
TEST:
EVAL_PERIOD: 490001
Results obtained:
| # Model | GPUs Number | Batch Size | Learning Rate | Spent time |
|---|---|---|---|---|
| Experiment 1 | 2 | 4 | 0.0005 | 18:26:09 |
| Experiment 2 | 2 | 4 | 0.002 | 18:20:29 |
| Experiment 3 | 2 | 16 | 0.002 | 2 days, 12:59:37 |
| Experiment 4 | 2 | 16 | 0.004 | 2 days, 12:57:23 |
- Evaluation results for bbox
| # Model | AP | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|
| BaseLine (densepose_rcnn_R_50_FPN_WC1_s1x) | 57.834 | 87.185 | 62.835 | 29.827 | 56.350 | 71.262 |
| Experiment 1 | 36.061 | 64.262 | 35.066 | 4.082 | 25.042 | 59.066 |
| Experiment 2 | 38.196 | 65.984 | 37.053 | 5.453 | 28.132 | 61.098 |
| Experiment 3 | 37.076 | 64.655 | 36.671 | 4.484 | 26.248 | 59.802 |
| Experiment 4 | 38.620 | 65.672 | 37.806 | 5.171 | 27.720 | 62.087 |
- Evaluation results for densepose
| # Model | AP | AP50 | AP75 | APm | APl |
|---|---|---|---|---|---|
| BaseLine (densepose_rcnn_R_50_FPN_WC1_s1x) | 49.817 | 86.501 | 51.651 | 44.205 | 51.085 |
| Experiment 1 | 15.256 | 38.203 | 10.238 | 0.433 | 16.329 |
| Experiment 2 | 19.759 | 46.102 | 14.561 | 0.561 | 21.107 |
| Experiment 3 | 19.442 | 45.604 | 14.654 | 0.877 | 20.756 |
| Experiment 4 | 23.333 | 52.020 | 17.726 | 1.399 | 24.926 |
Could you help me taking a look at my procedure + config + results above in order to give some advice on what I may be doing wrong??
Here are some pictures comparing the training processes:
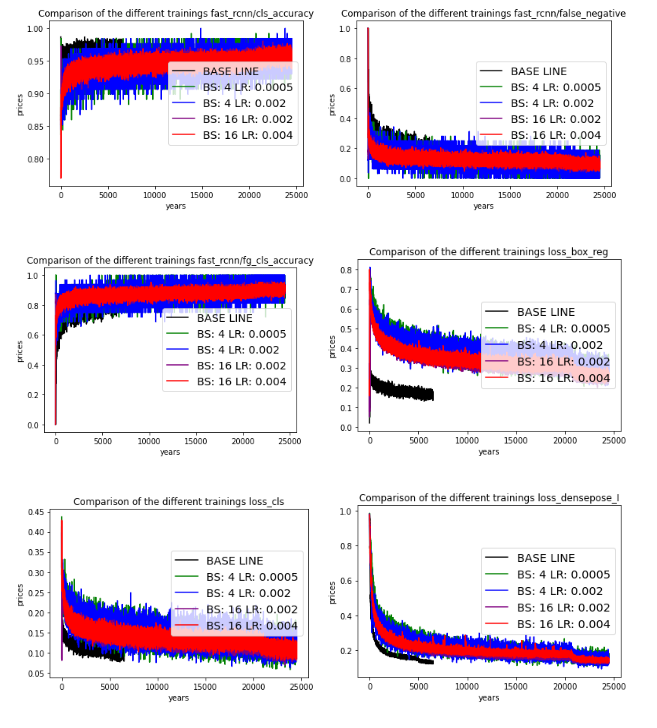
Also some comparisons of the results over a couple of images over here:

I haven’t try to run quantized training yet cause I expect to get similar metrics that the ones you’ve gotten before. I think they should not be as far away from baseline model metrics as they are right now.
Finally, I think that @favorxin also maybe interested in ^^ as I saw he was trying to do a similar work. Sharing more details with you guys over here Training results.pdf.
Thanks in advance!
Issue Analytics
- State:

- Created 2 years ago
- Reactions:4
- Comments:9 (2 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Hello, @gaitanignacio. Thanks for your efforts, I will rerun this/next week and report back
@favorxin Good point. Because one needs to add custom config fields. I copied from the detectron2 repo and slightly modified
apply_net.py. Check the latest commit, please.