
Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Flink SQL Error when trying to write a Flink changelog table to an Iceberg table
See original GitHub issueI’m facing some issues with writing a Flink changelog table to an Icberg table (maybe my query is wrong).
My Flink CDC query
CREATE TABLE shipments (
shipment_id INT,
origin STRING,
is_arrived BOOLEAN,
order_date DATE
) WITH (
'connector' = 'postgres-cdc',
'hostname' = 'dummy-db.us-east-1.rds.amazonaws.com',
'port' = '5432',
'username' = 'postgres',
'password' = '********',
'database-name' = 'postgres',
'schema-name' = 'public',
'table-name' = 'shipments',
'decoding.plugin.name'= 'pgoutput'
);
Creation of Iceberg table after I switch the catalog to my Iceberg catalog (catalog implementation is AWS Glue, confirmed that I’m able to connect to Glue Catalog).
CREATE TABLE shipments(
shipment_id INT,
origin STRING,
is_arrived BOOLEAN,
order_date DATE
)PARTITIONED BY (order_date);
Then I tried to insert the changelog table into the Iceberg table
Flink SQL> INSERT INTO iceberg.iceberg.shipments SELECT * FROM default_catalog.default_database.shipments;
[INFO] Submitting SQL update statement to the cluster...
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.TableException: AppendStreamTableSink doesn't support consuming update and delete changes which is produced by node TableSourceScan(table=[[default_catalog, default_database, shipments]], fields=[shipment_id, origin, is_arrived, order_date])
Issue Analytics
- State:

- Created 3 years ago
- Comments:6 (6 by maintainers)
 Top Results From Across the Web
Top Results From Across the Web
[GitHub] [iceberg] openinx edited a comment on issue #2172: Flink ...
[GitHub] [iceberg] openinx edited a comment on issue #2172: Flink SQL Error when trying to write a Flink changelog table to an Iceberg...
Read more >Enabling Iceberg in Flink
This creates an iceberg catalog named hive_catalog that can be configured using 'catalog-type'='hive' , which loads tables from a hive metastore: CREATE CATALOG ......
Read more >Newest 'iceberg' Questions - Stack Overflow
I am writing an apache iceberg table that is synced to a metastore. ... I have a Flink application that reads arbitrary AVRO...
Read more >Part 1: How Flink CDC Simplifies Real-Time Data Ingestion
However, if you want to facilitate data analysis, you need to merge the tables split from database and table splits into a large...
Read more >Streaming Data into Apache Iceberg Tables Using AWS ...
A recent article demonstrated how to create an Iceberg table using AWS Glue ... Apache Flink, Apache Spark Streaming, AWS Kinesis, and more....
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
@bkahloon , in this iceberg 0.11.0 release, we still don’t support exporting cdc events to iceberg by using flink SQL, but data stream is supported. Here is PR: https://github.com/apache/iceberg/commit/1b66bdfc084ac73fe999299d041aa2e5677f43c9.
Supporting the flink SQL will be the exact goal in 0.12.0 . For more details, you may be interested in this presentation: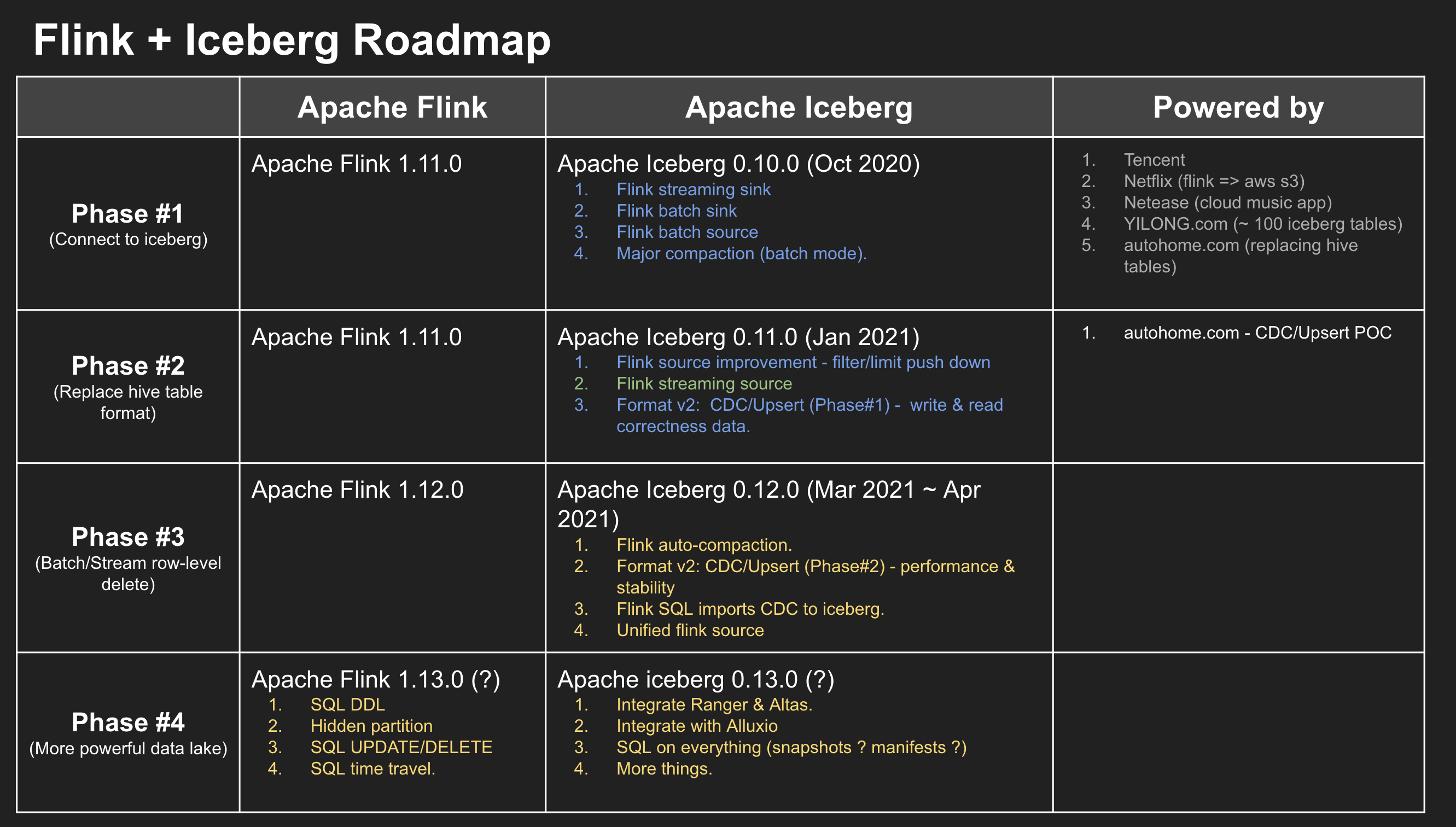
The slides share: https://docs.google.com/presentation/d/1X2KrzlAF4tsxuHHhL3OEN8EkvAb4sLdcXRxGsKFjPBY/edit#slide=id.p
@openinx Sorry, it was just an issue with how I implemented a custom debezium deserializer (wrong RowKind for some rows). After I fixed that everything works fine.
Could maybe help me understand this scenario. Lets say in the source db we only get like 10 rows inserted in the last 1 hour and we set our Flink checkpoint interval to 1 hr. Will FlinkSink just just commit a new parquet file with these 10 rows ?