
Stuck on an issue?
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Unable to query Iceberg data from Spark on EMR
See original GitHub issueI seem to be having some difficulties with integrating AWS Glue catalog and Flink. If I try to register an Iceberg catalog, databases or tables from the Flink SQL client the appropriate names show up in Glue catalog but the location field is not updated (preventing me from querying it using some other query engine).
To provide some more details this was my workflow:
- create an iceberg catalog, database and table from the sql client.
- Submit a flink datastream api job to write to this iceberg table, I just provide the table reference (also load the catalog) with the database.tablename reference (couldn’t use SQL because CDC wasn’t supported, see issue #2172)
- Flink is able to write to the appropriate s3 bucket and the metadata files are getting updated as well.
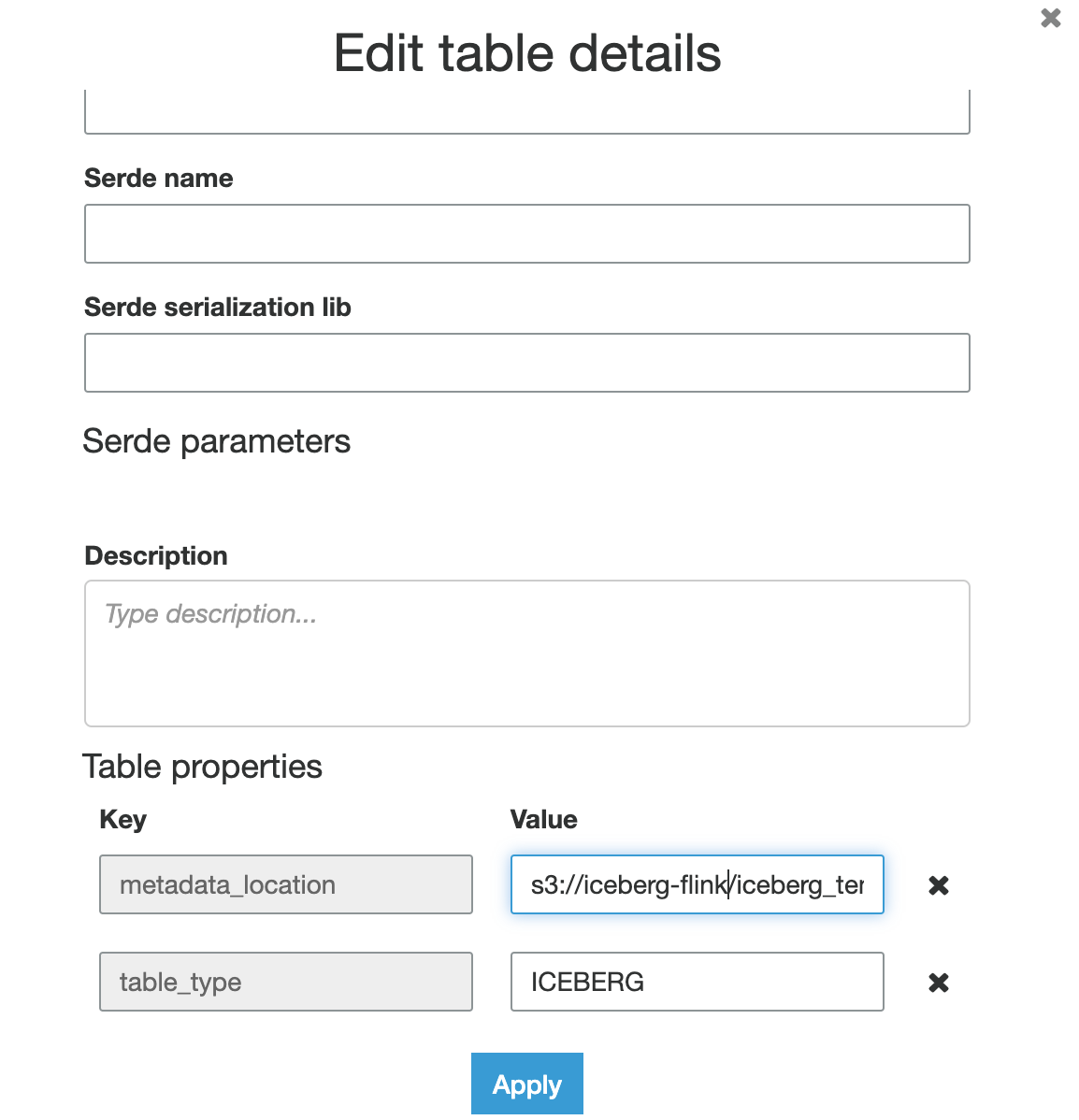
- When I look in the AWS Glue catalog UI, even though the table name shows up the table location, schema is not picked up in Glue.
The create catalog, database and table DDL queries I issued via the SQL client
CREATE CATALOG iceberg_catalog WITH (
'type'='iceberg',
'catalog-type'='iceberg',
'catalog-impl'='org.apache.iceberg.aws.glue.GlueCatalog',
'lock-impl'='org.apache.iceberg.aws.glue.DynamoLockManager',
'lock.table'='icebergGlueLockTable',
'warehouse'='s3://iceberg-flink'
);
create database iceberg_catalog.iceberg_temp;
CREATE TABLE iceberg_catalog.iceberg_temp.shipments_temp(
shipment_id INT,
origin STRING,
is_arrived BOOLEAN,
order_date DATE
)PARTITIONED BY (order_date);



Issue Analytics
- State:

- Created 3 years ago
- Comments:11 (10 by maintainers)
 Top Results From Across the Web
Top Results From Across the Web
Unable to query Iceberg table from PySpark script in AWS Glue
I'm trying to read data from an iceberg table, the data is in ORC format and partitioned by column. I'm getting this error...
Read more >Iceberg - Amazon EMR - AWS Documentation
Apache Iceberg is an open table format for large data sets in Amazon S3 and provides fast query performance over large tables, atomic...
Read more >Spark Writes - Apache Iceberg
Spark Writes. To use Iceberg in Spark, first configure Spark catalogs. Some plans are only available when using Iceberg SQL extensions in Spark...
Read more >Build an Apache Iceberg data lake using Amazon Athena ...
Create an EMR cluster · Select JupyterEnterpriseGateway and Spark as the software to install. · For Edit software settings, select Enter ...
Read more >AWS analytics Shortclip: Apache Iceberg on EMR (Hebrew)
Apache Iceberg is an open table format for large data sets in Amazon S3 and provides fast query performance over large tables, ...
Read more > Top Related Medium Post
Top Related Medium Post
No results found
 Top Related StackOverflow Question
Top Related StackOverflow Question
No results found
 Troubleshoot Live Code
Troubleshoot Live Code
Lightrun enables developers to add logs, metrics and snapshots to live code - no restarts or redeploys required.
Start Free Top Related Reddit Thread
Top Related Reddit Thread
No results found
 Top Related Hackernoon Post
Top Related Hackernoon Post
No results found
 Top Related Tweet
Top Related Tweet
No results found
 Top Related Dev.to Post
Top Related Dev.to Post
No results found
 Top Related Hashnode Post
Top Related Hashnode Post
No results found
For future users, the issue here was that the spark catalog was configured as “my_catalog” but the tables were being referred to in the session catalog which was not replaced with the Iceberg Spark SessionCatalog class.
There are two solutions
using the tripart identifier “catalogname.namespace.table”
or telling spark to use your catalog (whatever it’s name is) by default
“use my_catalog”
I don’t have an ETA for Glue side UI change yet, will reply when I have it. For Hive, it is probably worth trying to add the AWS module in Hive runtime, let me have a try in the next few days.