
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Fine-tuning procedure for mb_melgan vocoder, Voice Quality degrading with Fine-tuning.
See original GitHub issueHello! I’m trying to finetune a Vocoder model for Indian accents. I’ve followed the suggestions from thread #296 and have arrived at a suitable acoustics model.
To improve the output voice quality of the present vocoder( multiband_melgan.v1) model, I had followed the finetuning process mentioned in examples/multiband_melgan with 940000.h5 multiband_melgan.v1-EN as the pretrained model.
However the output has degraded(completely muffled speech) compared to the pretrained vocoder.
I had used the same dataset as the one used for fastspeech model training, with this command,
python ./examples/multiband_melgan/train_multiband_melgan.py \
--train-dir ./dump/train/ \
--dev-dir ./dump/valid/ \
--outdir ./examples/multiband_melgan/exp/train.multiband_melgan.v1/ \
--config ./examples/multiband_melgan/conf/multiband_melgan.v1.yaml \
--use-norm 1 \
--pretrained mb_melgan_generator.h5
These are the loss plots that I obtained,
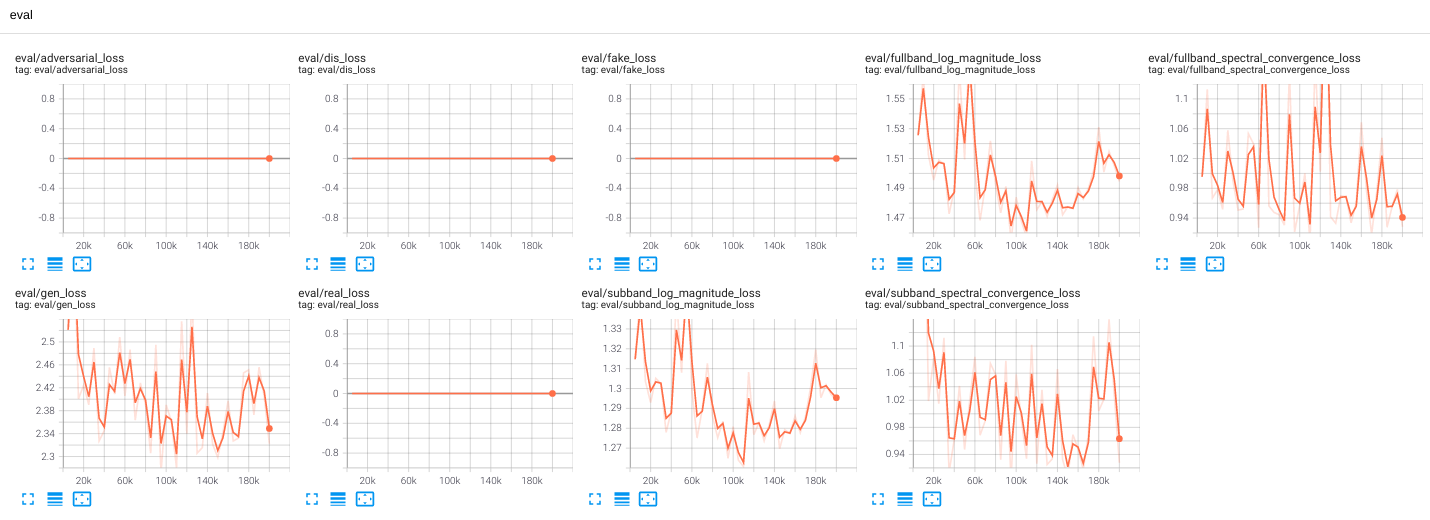
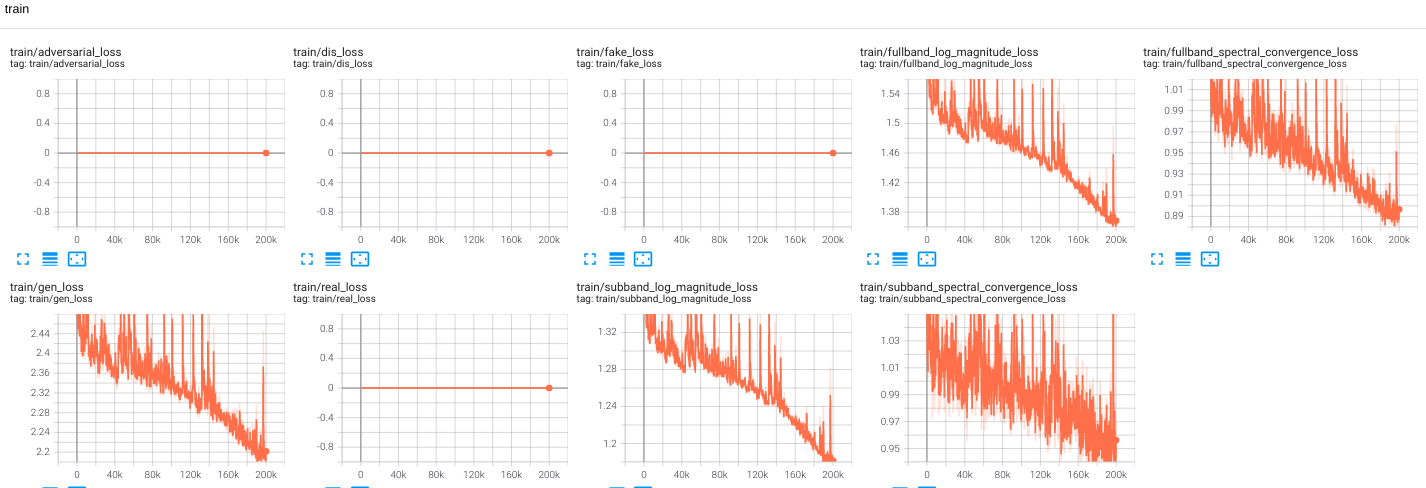
Please help me debug this problem, thank you
Issue Analytics
- State:

- Created 2 years ago
- Comments:5
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Thanks for the clarification @dathudeptrai 😃
yes 😄