
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Tacotron2 inference fails, but training evaluation seems fine
See original GitHub issueI’m training a Tacotron2 to perform duration extraction so that I can train FastSpeech2. I have a 5-hour custom non-English dataset that I prepared like LJSpeech (used default preprocessing). I’m training from scratch.
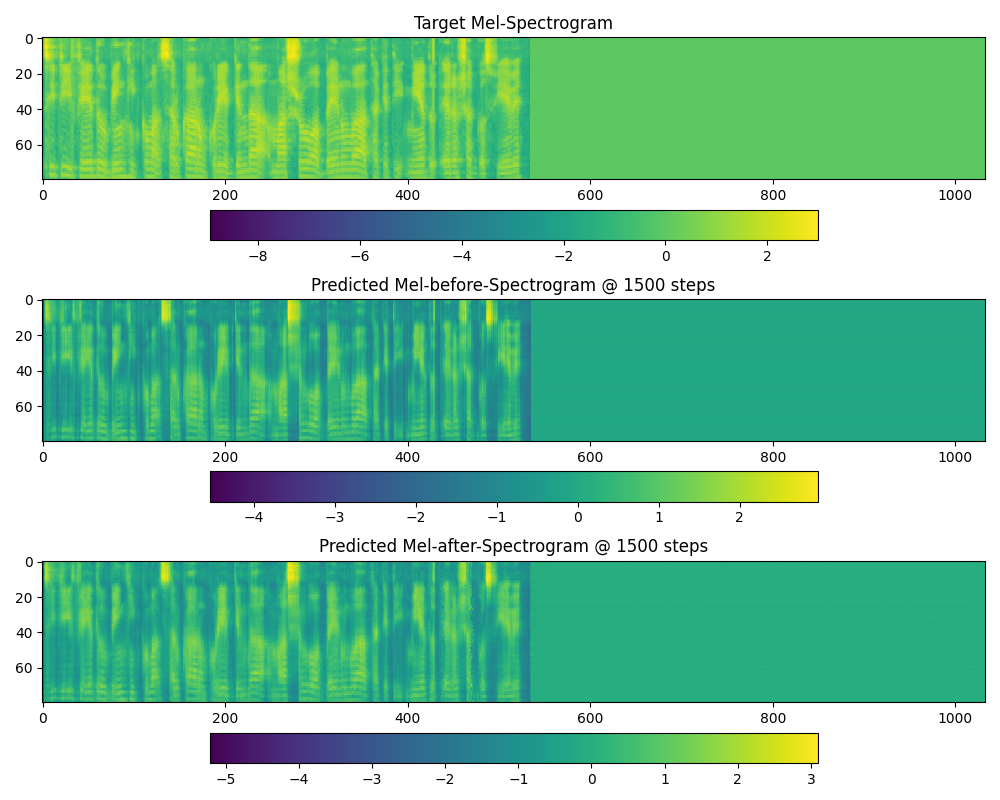
The alignments and the spectrograms generated during training seem fine, and so does the tensorboard outputs, as can be seen as follows:
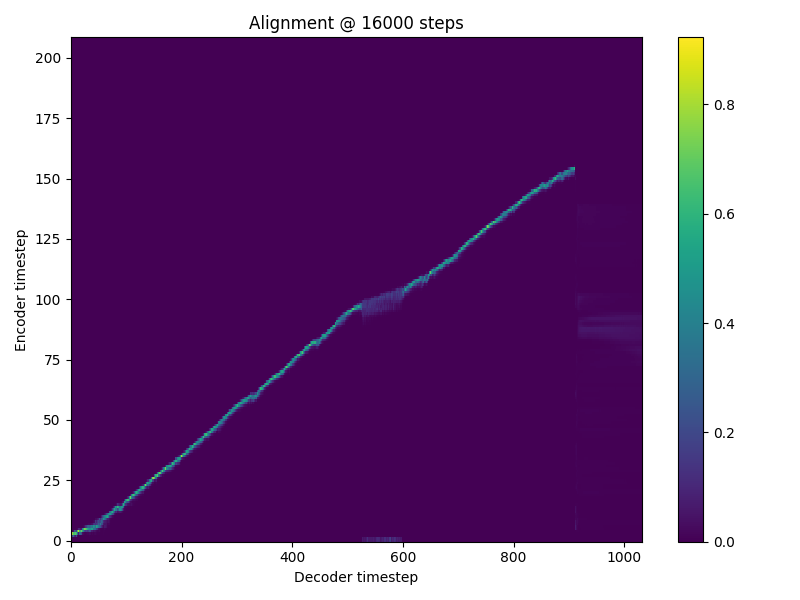 The spectrograms, though from 1,500 steps, have not deteriorated at 16,000 steps.
The spectrograms, though from 1,500 steps, have not deteriorated at 16,000 steps.

However, I get terrible results when I download a model (16,000 iterations) and perform inference. I created a Google Colab notebook for inference: https://colab.research.google.com/drive/1JLkncs27HaMo7dj05-T4cNW4u2nYAVWv?usp=sharing
The alignments and the spectrogram produced are as follows:
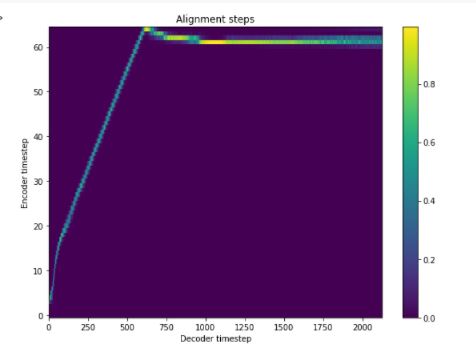
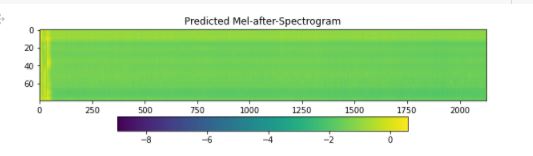
In the AutoProcessor, I used the ljspeech_mapper.json that I got from the dump_ljspeech folder. I used the tacotron2.v1.yml file that I found in the examples folder, as well.
As per what I understand from here, should I ignore this and keep training until 50k and then use the model to extract durations for FastSpeech2?
Issue Analytics
- State:

- Created 2 years ago
- Comments:5
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Thanks for the report 😄, it’s a good new since our pretrained models are valuable 🗡️
Just as an update: I guess that the dataset that I had used (~5,000 speech samples, total of 8 hours) was insufficient for the Tacotron to learn properly. I used the pretrained LJSpeech model and fine-tuned it on my dataset, and now I’m able to generate speech from Tacotron without using teacher-forcing.