
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
MB-MelGAN fine-tuning has big loss spikes, loss does not improve
See original GitHub issueHi,
I am trying to fine-tune the pretrained multiband_melgan.v1_24k model on LibriTTS + my speaker.
I’m aware that MB-MelGAN requires a lot more steps, but I am making this because my Tensorboard curve looks very unusual with spikes in loss, and no improvement in loss.
I am training on a machine with Xeon E5-2623 v4 + 4x1080ti + 128GB RAM, so memory should not be an issue this time. (on this topic, should I be seeing just 4it/s on this hardware?)
Attempt 1:
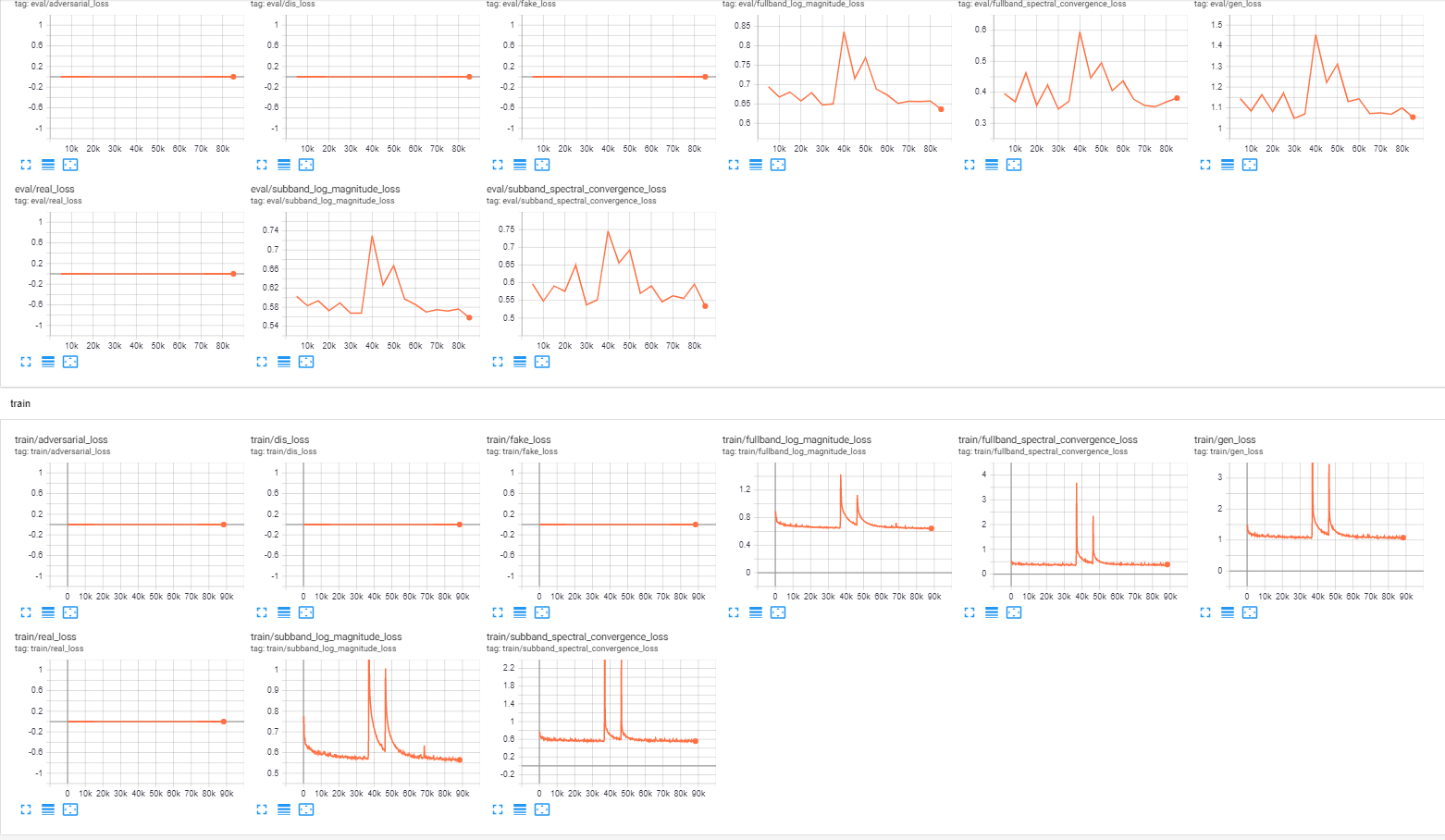
(These logs are from another training session, but the same problems happen)
2020-11-10 02:02:00,529 (base_trainer:566) INFO: (Step: 2400) train_subband_spectral_convergence_loss = 0.6038.
2020-11-10 02:02:00,534 (base_trainer:566) INFO: (Step: 2400) train_subband_log_magnitude_loss = 0.6201.
2020-11-10 02:02:00,538 (base_trainer:566) INFO: (Step: 2400) train_fullband_spectral_convergence_loss = 0.4016.
2020-11-10 02:02:00,543 (base_trainer:566) INFO: (Step: 2400) train_fullband_log_magnitude_loss = 0.7134.
2020-11-10 02:02:00,548 (base_trainer:566) INFO: (Step: 2400) train_gen_loss = 1.1694.
2020-11-10 02:02:00,552 (base_trainer:566) INFO: (Step: 2400) train_real_loss = 0.0000.
2020-11-10 02:02:00,557 (base_trainer:566) INFO: (Step: 2400) train_fake_loss = 0.0000.
2020-11-10 02:02:00,562 (base_trainer:566) INFO: (Step: 2400) train_dis_loss = 0.0000.
^M[train]: 0%| | 2401/4000000 [10:32<292:02:52, 3.80it/s]^M[train]: 0%| | 2402/4000000 [10:33<269:08:44, 4.13it/s]^M[train]: 0%| | 2403/4000000 [10:33<265:15:08, 4.19it/s]^M[train]: 0%| | 2$
^M[train]: 0%| | 2521/4000000 [10:58<658:17:57, 1.69it/s]^M[train]: 0%| | 2522/4000000 [10:58<519:10:25, 2.14it/s]^M[train]: 0%| | 2523/4000000 [10:58<424:09:18, 2.62it/s]^M[train]: 0%| | 2$
2020-11-10 02:02:41,702 (base_trainer:566) INFO: (Step: 2600) train_subband_spectral_convergence_loss = 9.2314.
2020-11-10 02:02:41,706 (base_trainer:566) INFO: (Step: 2600) train_subband_log_magnitude_loss = 1.1278.
2020-11-10 02:02:41,711 (base_trainer:566) INFO: (Step: 2600) train_fullband_spectral_convergence_loss = 2.4215.
2020-11-10 02:02:41,716 (base_trainer:566) INFO: (Step: 2600) train_fullband_log_magnitude_loss = 1.2601.
2020-11-10 02:02:41,720 (base_trainer:566) INFO: (Step: 2600) train_gen_loss = 7.0204.
2020-11-10 02:02:41,725 (base_trainer:566) INFO: (Step: 2600) train_real_loss = 0.0000.
2020-11-10 02:02:41,730 (base_trainer:566) INFO: (Step: 2600) train_fake_loss = 0.0000.
2020-11-10 02:02:41,734 (base_trainer:566) INFO: (Step: 2600) train_dis_loss = 0.0000.
^M[train]: 0%| | 2601/4000000 [11:14<253:23:40, 4.38it/s]^M[train]: 0%| | 2602/4000000 [11:14<244:25:47, 4.54it/s]^M[train]: 0%| | 2603/4000000 [11:14<229:49:07, 4.83it/s]^M[train]: 0%| | 2$
2020-11-10 02:03:19,283 (base_trainer:566) INFO: (Step: 2800) train_subband_spectral_convergence_loss = 1.1394.
2020-11-10 02:03:19,288 (base_trainer:566) INFO: (Step: 2800) train_subband_log_magnitude_loss = 1.0550.
2020-11-10 02:03:19,294 (base_trainer:566) INFO: (Step: 2800) train_fullband_spectral_convergence_loss = 0.9998.
2020-11-10 02:03:19,299 (base_trainer:566) INFO: (Step: 2800) train_fullband_log_magnitude_loss = 1.1900.
2020-11-10 02:03:19,304 (base_trainer:566) INFO: (Step: 2800) train_gen_loss = 2.1921.
2020-11-10 02:03:19,310 (base_trainer:566) INFO: (Step: 2800) train_real_loss = 0.0000.
2020-11-10 02:03:19,315 (base_trainer:566) INFO: (Step: 2800) train_fake_loss = 0.0000.
2020-11-10 02:03:19,320 (base_trainer:566) INFO: (Step: 2800) train_dis_loss = 0.0000.
Is this normal behaviour?
Issue Analytics
- State:

- Created 3 years ago
- Comments:5 (3 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
@OscarVanL it’s normal 😃). After 200k, the model will stop and you need re-sume it then it will training both Generator and Discriminator, it should train around 1M steps to get best performance.
@aragorntheking
Yes it did, in particular, it reduced the buzzing/noise in the background.
I did not restrict any layers, I just started the training job over the pretrained
multiband_melgan.v1_24kvocoder.I did train with all speakers, not just my 1 voice. It did improve performance in general.
I think with just one voice it’s likely to overfit (obviously, this depends on how much speech you have for that speaker), hence why all speakers performed better for me.