
Lightrun Answers was designed to reduce the constant googling that comes with debugging 3rd party libraries. It collects links to all the places you might be looking at while hunting down a tough bug.
And, if you’re still stuck at the end, we’re happy to hop on a call to see how we can help out.
Pooling Strategy Question
See original GitHub issueIn the Original S-BERT paper, you mentioned
“Researchers have started to input individual sentences into BERT and to derive fixed size sentence embeddings. The most commonly used approach is to average the BERT output layer (known as BERT embeddings) or by using the output of the first token (the [CLS] token). As we will show, this common practice yields rather bad sentence embeddings, often worse than averaging GloVe embeddings (Pennington et al., 2014).”
When you say the average the BERT output layer do you mean the average pooling of the last layer's hidden state? if so how is it different from what Sentence Transformer does? Doesn’t Sentence Transformers by default use average (mean) pooling on tokens of the last layer’s hidden state (and optionally supports max pooling and CLS pooling if I am not wrong. )
So I am confused when you say before sentence transformers,
researchers used to get fixed dimensions by commonly used approach is to average the BERT output layer (known as BERT embeddings)
Also, the BERT author hints (below) at the average pooling of word (or token) embeddings may not yield a good sentence embedding. All along I was under the impression this is what sentence transformed mean pooling does to get sentence embeddings.
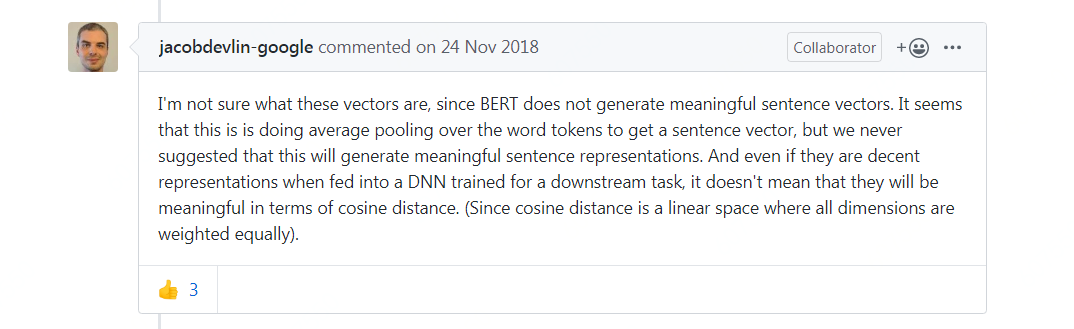
Could you please clarify?
Issue Analytics
- State:

- Created a year ago
- Comments:6 (3 by maintainers)
 Top Related StackOverflow Question
Top Related StackOverflow Question Troubleshoot Live Code
Troubleshoot Live Code Top Related Reddit Thread
Top Related Reddit Thread Top Related Hackernoon Post
Top Related Hackernoon Post Top Related Tweet
Top Related Tweet Top Related Dev.to Post
Top Related Dev.to Post Top Related Hashnode Post
Top Related Hashnode Post
Not sure if I get the question. The output of BERT is averaged. But BERT needs fine-tuning on suitable data to produce meaningful text embeddings.
Understood, thanks