
The 7 Most Common Python Debugging Challenges and How to Handle Them
Python: Literally Out of This World
According to PYPL (PopularitY of Programming Language), Python has been the most popular programming language worldwide from 2018 to the present.
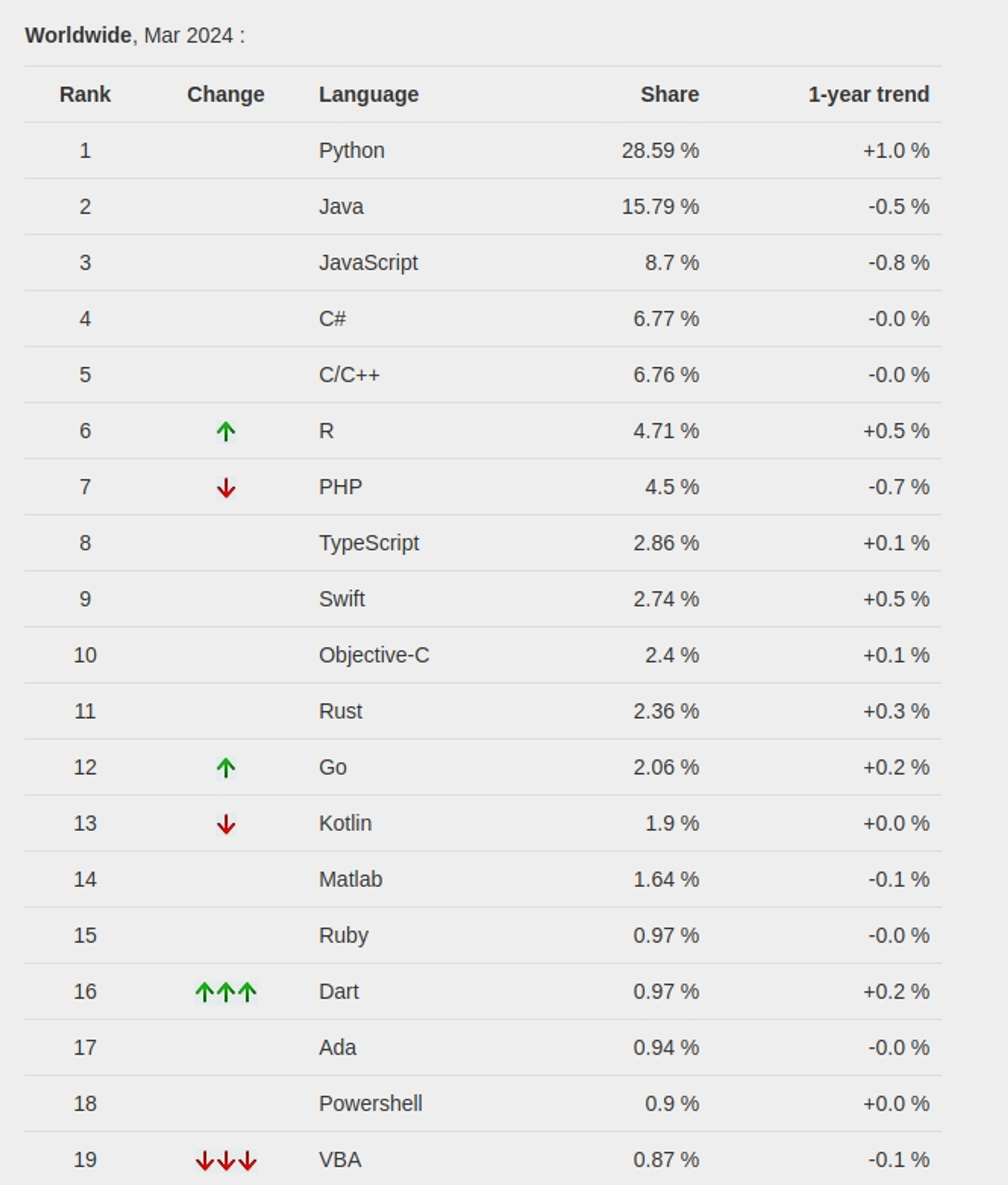
PYPL ranking of programming languages on March 2024 (source PYPL)
Remarkably, Python’s popularity has grown by 2.5% over the last five years. In contrast, Java, the previously most popular language, has seen a 4.8% decrease in its popularity.
While Java is typically faster than Python, Python is easier to read with its simpler syntax.
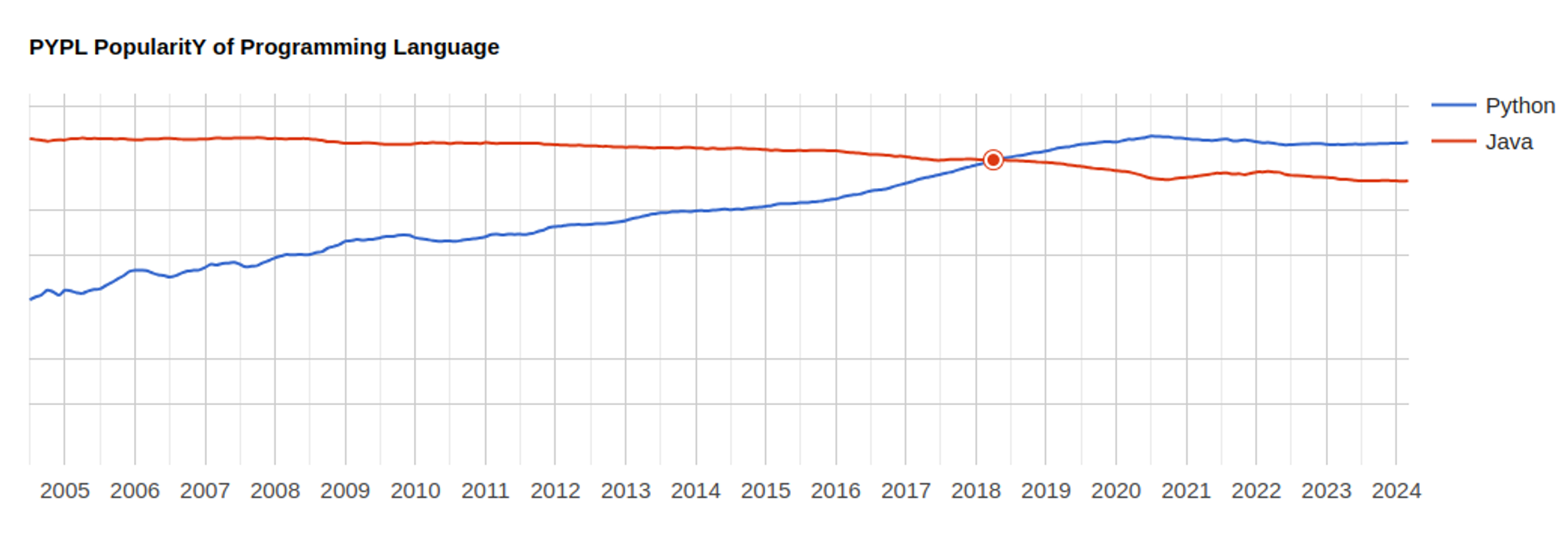
Python has been the most popular language since 2018 (source PYPL)
One of its major strengths is its versatility across various fields, such as API and web development, AI/ML, data science, IoT, and DevOps.A notable example that shows the multidisciplinary nature of this programming language is NASA‘s use of Python’s Astropy for data analysis with the advanced James Webb Space Telescope.
Back to Earth: Python’s Debugging Challenges
While Python excels in readability and versatility, it doesn’t perform as well as compiled languages like C and C++ in terms of speed. The chief bottleneck typically arises from the fact that Python is an interpreted language, directly translating into slower execution times of CPU-intensive work. An interpreted language is directly executable without prior compilation of a machine-level program.
Running Python as an interpreted language enhances the developer’s experience and increases development flexibility. It also brings along its set of problems, such as in the case of debugging. While other compiled languages receive a check at compile time, which flags any errors, many Python issues often become apparent only at runtime.
In the following sections, we will explore some additional debugging challenges that are common among Python developers.
The code examples illustrating these challenges will utilize Flask and FastAPI frameworks. To better emphasize these challenges, the code samples will be abstracted as much as possible.
Keep reading!
1. Handling Global Variable Modification
Global variables are bad in any programming language. Don’t get me wrong here, I’m not referring to the global constants which are fine. To better illustrate this, let’s focus on the following code:
######################################
# Global variable modification issue #
######################################
counter = 0
@app.route('/increment', methods=['GET'])
def increment_global_counter():
global counter
counter += 1
return f"Counter is now: {counter}
While this code might seem straightforward and perfectly fine for demonstrating basic Python functionality or for simple scripts, it can present challenges in a real-world web application. The problem with modifying global variables like a counter in a web server environment is that it can lead to race conditions when multiple requests are handled simultaneously. This is because web servers often serve multiple requests in parallel, using threads or asynchronous routines (e.g.: A Flask web app running on Gunicorn). When two requests try to increment the counter at the same time, they may read, increment, and write back the same value, leading to an incorrect total count. More appropriate mechanisms for state management, such as database systems or in-memory data stores like Redis are designed to handle concurrent accesses safely.Sometimes, you learn through trial and error. However, it’s important to use the right debugging tool such as Lightrun that offers features like dynamic logging and on-demand snapshots. This allows you to gather system state information without needing to redeploy your code for each new debugging line added. The screenshot below shows how to use Lightrun’s dynamic logging to get the value of the counter from a remote environment (”prod” in our case) without leaving VSCode.
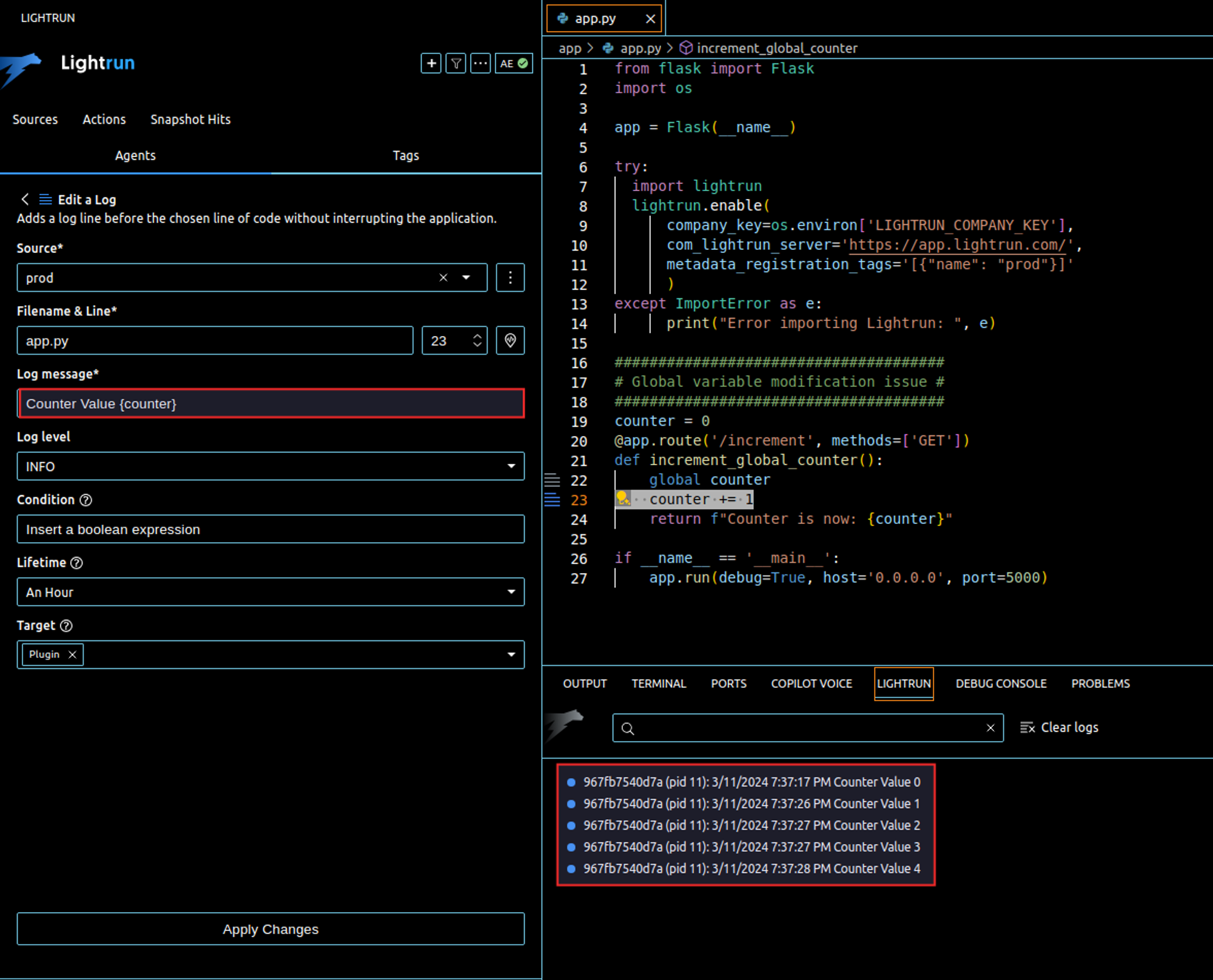
2. Errors Are Only Visible at Runtime
As mentioned earlier, since Python is interpreted rather than compiled, some errors only become apparent at runtime. Consider this example:
######################################
# Type error only visible at runtime #
######################################
@app.route('/add', methods=['GET'])
def add():
a = 10
b = "20"
c = a + b
return cThe error stems from attempting to add an integer (a) to a string (b), a type mismatch that Python will only catch once the program is running. This type of error, common in dynamically typed languages like Python, illustrates developers’ challenges with runtime errors. The interpreter does not identify the mistake during coding until deployment or live use. This necessitates thorough testing and using additional tools such as Lightrun when your code becomes complex.
With Lightrun snapshot, we can examine the state of the variables at runtime from any local or remote environment without stopping the application, to do this, right-click on the line where the operation is made (c = a + b), add a snapshot and configure it as shown in the below screenshot:
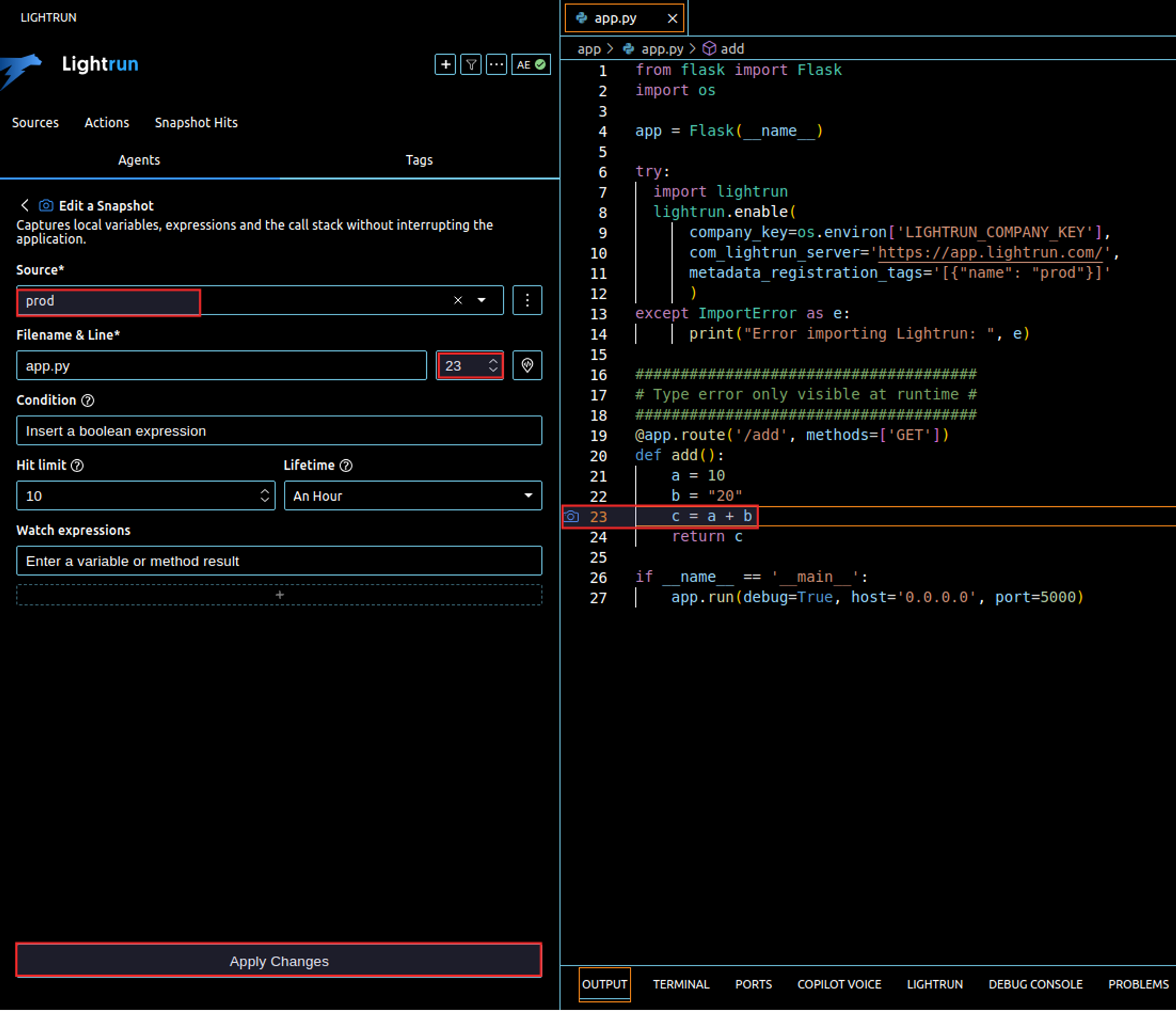
Each time a request is made using the /add/ route, Lightrun creates a snapshot hit. This snapshot can be accessed from your IDE, showing the current state of your application at a particular stage. In this example, the snapshot shows that a is, in fact, an integer while b is a string.
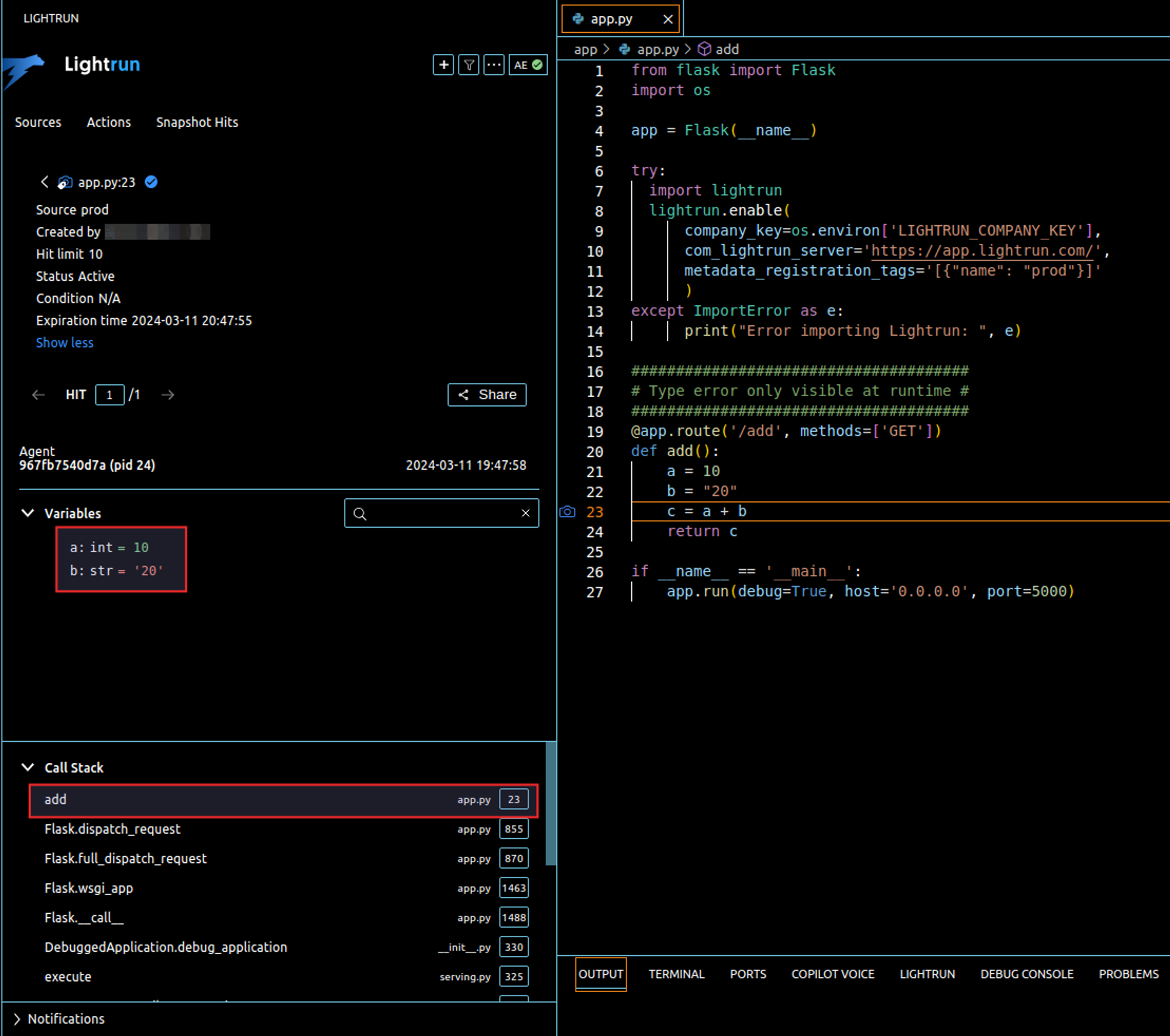
Snapshots behave almost like breakpoints in a traditional debugger, though in this case, they can log states at any portion of code that it relates to in the application. A snapshot with each activation includes stack traces and all the values of available variables: local variables, function arguments, and attributes of objects belonging to the stack. Furthermore, you can add a condition so that Lightrun only takes a snapshot when the condition is met. This feature can be used in this way to clean out the noise and take up just the necessary information. It can be particularly beneficial in situations like debugging issues that occur for specific users or under certain circumstances.
Here’s the distinction: Unlike old-style debugger breakpoints that put the application and all threads into a waiting state, snapshots are taken without causing any blockage. They are just documentary records of how the execution of the application looked at that time, not blocking like most debugger operations cause to the application.
While usually debugger breakpoints can temporarily stop an application either at the thread level or with the whole application to inspect it, the Lightrun way ensures normal application continuous operation, and simple real-time diagnostics without any sort of downgrade in application performance and user experience.
While the above example is simple for illustration purposes, understanding the specific types and states of variables during an error is crucial in more complex situations. Lightrun assists in identifying not only type mismatches but also logical errors that may not be immediately obvious. For instance, if a function expects a list but receives a dictionary, or when handling complicated data structures and asynchronous operations, the ability to inspect the application’s state in real time without disrupting its flow is priceless.
3. Unhandled Exceptions
Unhandled exceptions are a common problem in many Python applications. These exceptions occur when an error is not caught and handled in the code, causing the application to crash unexpectedly. The challenge here is that these exceptions can be hard to predict and replicate. It’s crucial to have robust error handling and logging mechanisms in place to mitigate this issue.
########################
# Unhandled exceptions #
########################
@app.route('/divide', methods=['GET'])
def divide():
numerator = request.args.get('numerator', default=1, type=int)
denominator = request.args.get('denominator', default=0, type=int)
# Potential ZeroDivisionError
result = numerator / denominator
return f"Result: {result}"
The ZeroDivisionError in the divide route example provided above, can lead to server errors and a poor user experience in real-world applications. This specific example illustrates a scenario where dividing by zero, a common mathematical error, is not explicitly handled. Lightrun allows developers to effectively debug such issues by adding a dynamic log line or a snapshot right before potential crash points in our code. For instance, in the /divide route, we could dynamically log the request parameters or capture the state of the variables used in the divide function. Here is an example of a curl request snapshot, which only sends the numerator and lets the denominator take its default value:
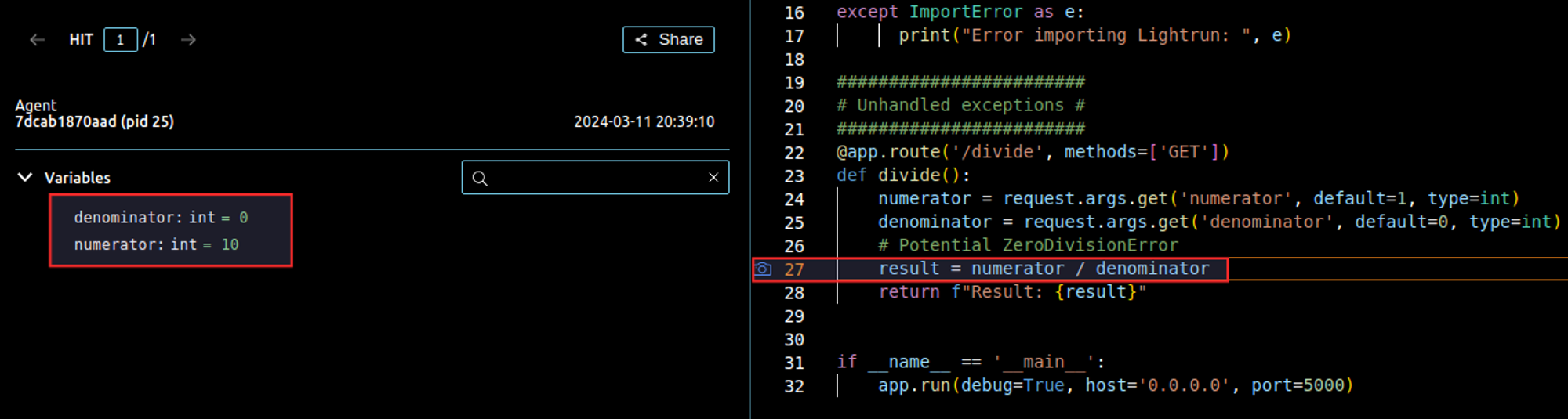
Similarly to what we have seen in the previous examples, this would allow you to debug and observe exceptions gracefully without having to redeploy.
4. Mutable Default Arguments in Python
The mutable default argument issue is a common pitfall in Python. It often leads to unexpected behavior, especially for those new to the language. Some even call this “the source of all evil“.
Consider the following example to illustrate this concept:
####################################
# Mutable default argument problem #
####################################
@app.route('/append', methods=['GET'])
def append_to(to=[]):
element = request.args.get('element')
to.append(element)
return t
In the provided example, the function append_to is designed to append an element to a list. However, it uses a mutable list as a default argument. This can cause unexpected results because default argument values are evaluated only once when the function is defined, not each time the function is called. Therefore, if append_to is called multiple times without specifying the to argument, it will keep appending to the same list rather than starting with an empty list each time.
5. Deadlocks in Concurrent Applications
The following example illustrates two routes (/deadlock1 and /deadlock2) that are trying to acquire locks (lock_a and lock_b) in the opposite order. This could potentially lead to a deadlock if they are called concurrently.
######################
# Deadlock condition #
######################
from threading import Lock
import time
lock_a = Lock()
lock_b = Lock()
resource_a = {"value": 0}
resource_b = {"value": 0}
@app.route('/deadlock1', methods=['GET'])
def update_resources_deadlock1():
with lock_a:
# Simulated operation on resource_a
resource_a["value"] += 1
time.sleep(1) # Simulate operation delay
with lock_b:
# Simulated operation on resource_b
resource_b["value"] += 1
return "Resources updated successfully in deadlock1"
@app.route('/deadlock2', methods=['GET'])
def update_resources_deadlock2():
with lock_b:
# Simulated operation on resource_b
resource_b["value"] += 1
time.sleep(1) # Simulate operation delay
with lock_a:
# Simulated operation on resource_a
resource_a["value"] += 1
return "Resources updated successfully in deadlock2
To prevent deadlocks in such scenarios, some strategies could be used. For example, you need to ensure that locks are always acquired in the right order across your application. You can also implement a timeout on locks – the Python threading library provides mechanisms to attempt to acquire a lock with a timeout. You can also attempt to acquire the lock without blocking. If the lock is not available, release any currently held locks and retry after a delay. Before selecting the optimal solution, particularly in real-world applications where code design is more complex than the example provided above, experimenting with your code and exploring all potential scenarios is the best approach.
6. Race Conditions in Database Operations
Let’s imagine you are creating a personal finance management application. At a certain level, you need to update the user’s balance. This is a code sample that can be used to implement this feature:
##############################################
# Race Conditions in Concurrent Environments #
##############################################
from sqlalchemy.exc import SQLAlchemyError
from mydatabase import db_session, User
@app.route('/update_balance/<user_id>', methods=['POST'])
def update_balance(user_id):
new_transaction_amount = request.json['amount']
try:
user = db_session.query(User).filter(User.id == user_id).first()
if user:
user.balance += new_transaction_amount # Potential race condition
db_session.commit()
return {"status": "Balance updated successfully"}, 200
else:
return {"error": "User not found"}, 404
except SQLAlchemyError as e:
db_session.rollback()
return {"error": str(e)}, 50
Imagine two (or more) requests arrive almost simultaneously at the server, each intending to update the balance of the same user. Let’s say both requests are to add 100 to the current balance of 500. Each request starts by reading the user’s current balance from the database. Since these operations happen almost simultaneously, both read the same initial balance of 500. Each request then proceeds to modify the balance in memory, adding 100 to the 500 read earlier. Both requests now have a modified balance of 600, independently and unaware of each other’s modifications. Finally, both requests attempt to write back the new balance to the database. The last write operation to be committed will overwrite any previous writes. In this case, both requests write the value 600 as the new balance. The expected behavior, with two additions of 100, is to have a final balance of 700.
Here’s an updated version of our code that includes row-level locking:
from flask import Flask, request, jsonify
from sqlalchemy.exc import SQLAlchemyError
from mydatabase import db_session, User
@app.route('/update_balance/<user_id>', methods=['POST'])
def update_balance(user_id):
new_transaction_amount = request.json['amount']
try:
# Lock the user row during the transaction to prevent race conditions
user = db_session.query(User).filter(User.id == user_id).with_for_update().first()
if user:
user.balance += new_transaction_amount
db_session.commit()
return jsonify({"status": "Balance updated successfully"}), 200
else:
return jsonify({"error": "User not found"}), 404
except SQLAlchemyError as e:
db_session.rollback()
return jsonify({"error": str(e)}), 500
Another approach is using database transactions – the latter ensures that all operations within it either complete successfully as a whole or are rolled back if any fail. In SQLAlchemy, a session facilitates transactions:
Session = sessionmaker(bind=engine)
session = Session()
try:
# Perform database operations
user = session.query(User).filter(User.id == user_id).one()
user.balance += transaction_amount
# The commit will attempt to write changes to the database
session.commit()
except:
# If an error occurs, roll back the changes
session.rollback()
raise
finally:
# Ensure that the session is closed
session.close()7. Incorrect Usage of Async Functions
Async functions in Python, defined with the async def syntax, are meant to be used within an asynchronous context. They must be awaited using the await keyword, allowing Python to pause the function execution at the await expression, perform other tasks, and then come back to continue execution once the awaited task is completed.
However, as non-async functions are the norm, with no need for the await keyword, developers frequently overlook the necessity of its inclusion. Though it might seem like a small-bore detail, this aspect is commonly neglected due to inattention. These are the types of issues that are hard to detect. Your code may look fine when you read it, but it doesn’t execute correctly.
For the sake of simplicity, we are using FastAPI in the following example because it natively supports asynchronous functions:
#####################################
# Incorrect usage of async function #
#####################################
from fastapi import FastAPI
import asyncio
app = FastAPI()
async def fetch_data():
# Simulate a network operation using asyncio.sleep
await asyncio.sleep(1) # Simulates a network call delay
return "Data fetched"
@app.get("/fetch")
async def fetch():
# Incorrect usage: missing await keyword when calling an async function
data = fetch_data()
return data
The correct way to utilize fetch_data within an asynchronous FastAPI route would involve using the await keyword:
@app.get("/fetch")
async def fetch():
# Correct usage: await the result of the async function
data = await fetch_data()
return dataEmbrace Shifting Developer Observability Left
The common line of all these indicative scenarios throughout is that the serious degradation in user experience or performance of the application is generally realized only during the actual execution of the code.
In fact, errors due to missing or rogue code appear during runtime in Python code, as there are no compile-time checks like in compiled languages. In this case, a tool that allows Python developers to observe application behavior in real-time becomes absolutely mandatory in the Python programmer’s armory. Dynamic logging, expression evaluation, and checking of any code-level object—all of this should occur seamlessly, without the need for application redeployment. That’s exactly where Lightrun comes into play:
With Lightrun Developer Observability, you can add a dynamic log statement around a variable in each of its usages. This allows you to trace its value through the flow, track down unwanted modifications, or simply satisfy your curiosity regarding how the value is affected by concurrent access. You can add real-time log statements inside try/except blocks to capture values of variables that cause exceptions. Use snapshot to capture the state of your application at a given point without stopping or slowing it down, and much more.
Additionally, Lightrun is well-suited for Python. Given that many Python errors are only identifiable at runtime due to its interpreted nature, and Lightrun specializes in real-time logs and trace dynamic instrumentation within runtime environments without redeployment, it is especially beneficial for Python development. This compatibility is particularly valuable within the Python ecosystem, where dynamic typing and runtime evaluations are central.
Lightrun is compatible not only with vanilla Python code, but also supports frameworks and tools from the same ecosystem such as Django, Flask, Celery, Airflow, Gunicorn, and Serverless Python functions.
*** By integrating these capabilities, Lightrun shifts observability left and facilitates a more proactive and efficient debugging process, empowering developers to get real-time insights from their Python code to identify, diagnose, and resolve issues faster and with greater precision.
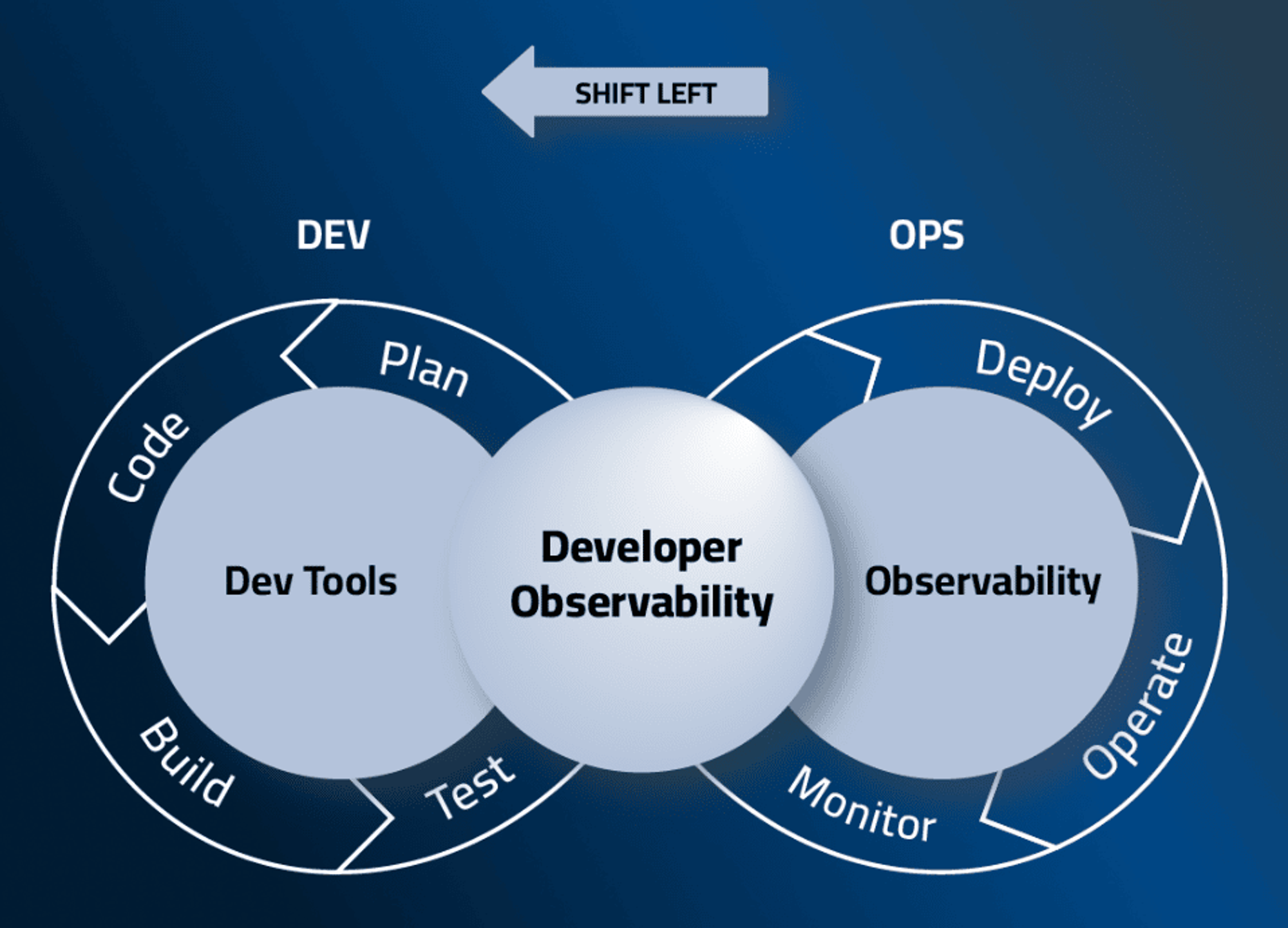
To see Lightrun in action, you can request a demo here. Alternatively, you can check out our Playground to experiment with Lightrun in a live app without any configuration needed. Watch the video below to see how easy it is to use Lightrun straight from VSCode. Other IDEs are also supported.



It’s Really not that Complicated.
You can actually understand what’s going on inside your live applications.